
Prince Addo
PhD student, Process Control
Chemical and Materials Eng DeptUniversity of AlbertaEdmonton AB
230Donadeo Innovation Centre For Engineering
9211-116 St, Edmonton AB
T6G 2H5
I am currently a PhD student at the Chemical and Materials Engineering Department of the University of Alberta. My research interests are in process control (mainly statistical), machine learning, and modelling and simulation of chemical processes. I am also interested in software, application and web development.
Previously, I completed my masters at the Process Engineering Department of Stellenbosch University. My research interests are in process control (mainly statistical), machine learning, and modelling and simulation of chemical processes. I am also interested in software and web development.
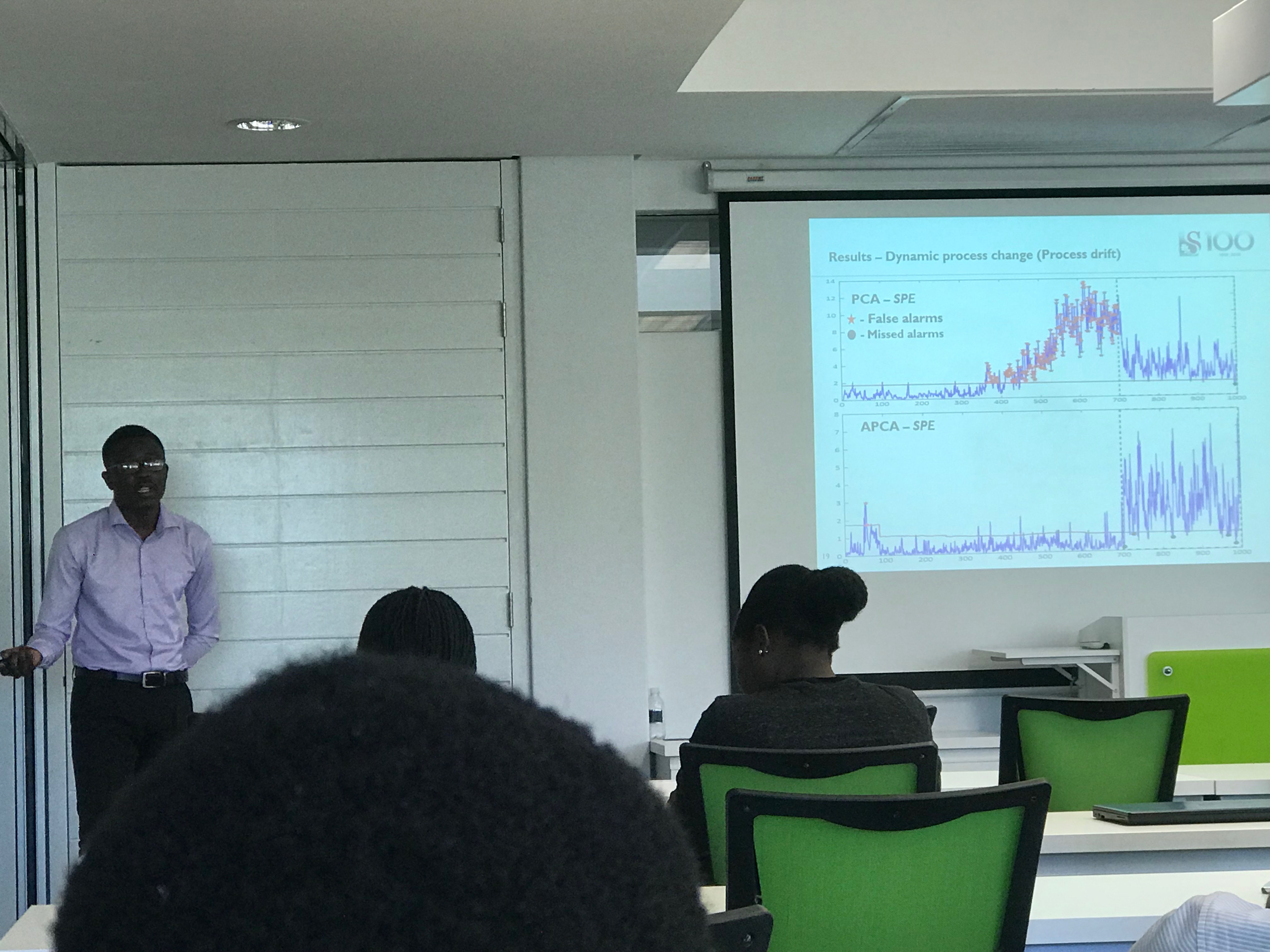
My master's work was on adaptive process monitoring with data-driven approaches, in which a novel monitoring approach that caters for slow and sudden process changes was developed. The work was funded by Sasol and The Center for Artificial Intelligence Research, South Africa, with notable contributions by the people listed below.

Dr. Lidia Auret
Data Science and Process Manager
Stone Three Digital
South Africa

Dr. Steve Kroon
Senior Lecturer
Department of Computer Science
Stellenbosch University

Dr. Roelof Coetzer
Senior Manager
Industrial Statistics
Sasol Group Technology

Dr. John McCoy
Data Scientist
Stone Three Digital
South Africa
- PhD Process Control, University of Alberta (2020 - Present)
- M.Eng. Extractive Metallurgical Engineering, Stellenbosch University (2017 - 2019)
- B.Sc. Petrochemical Engineering, Kwame Nkrumah University of Science and Technology (2012 - 2016)
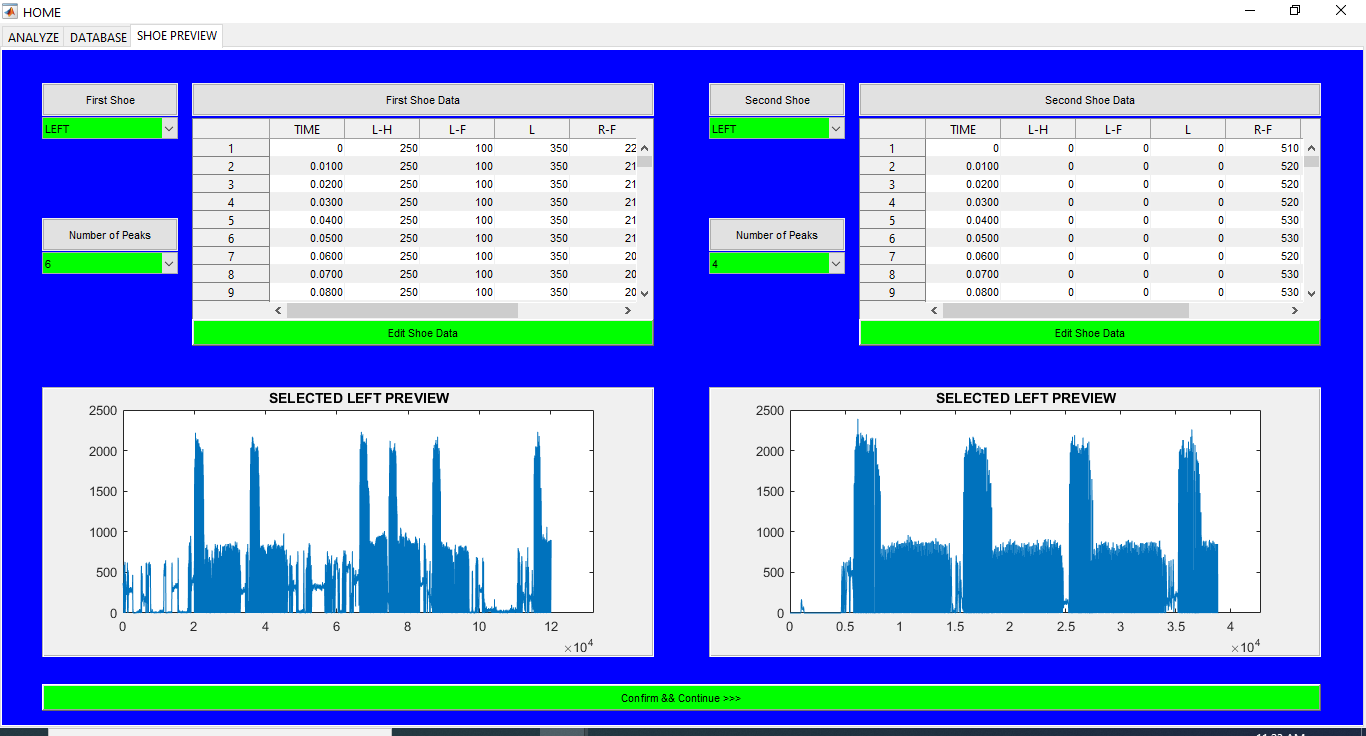
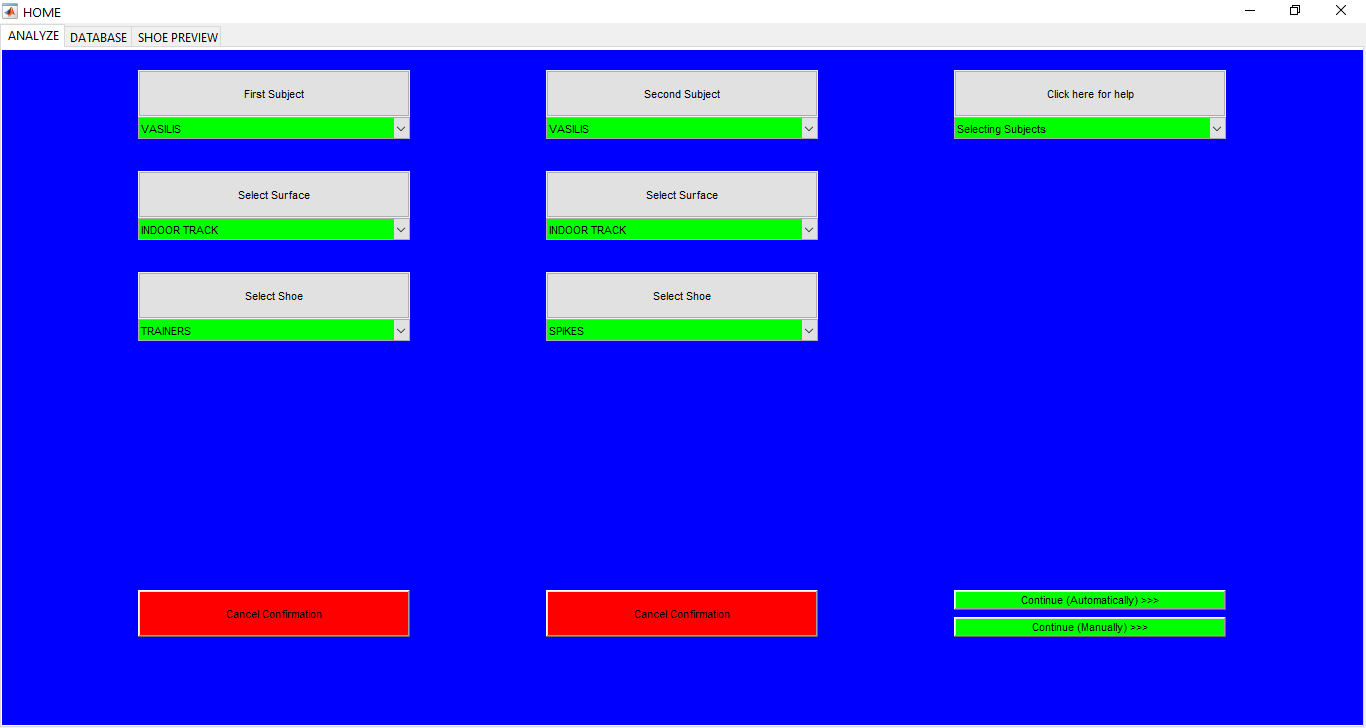
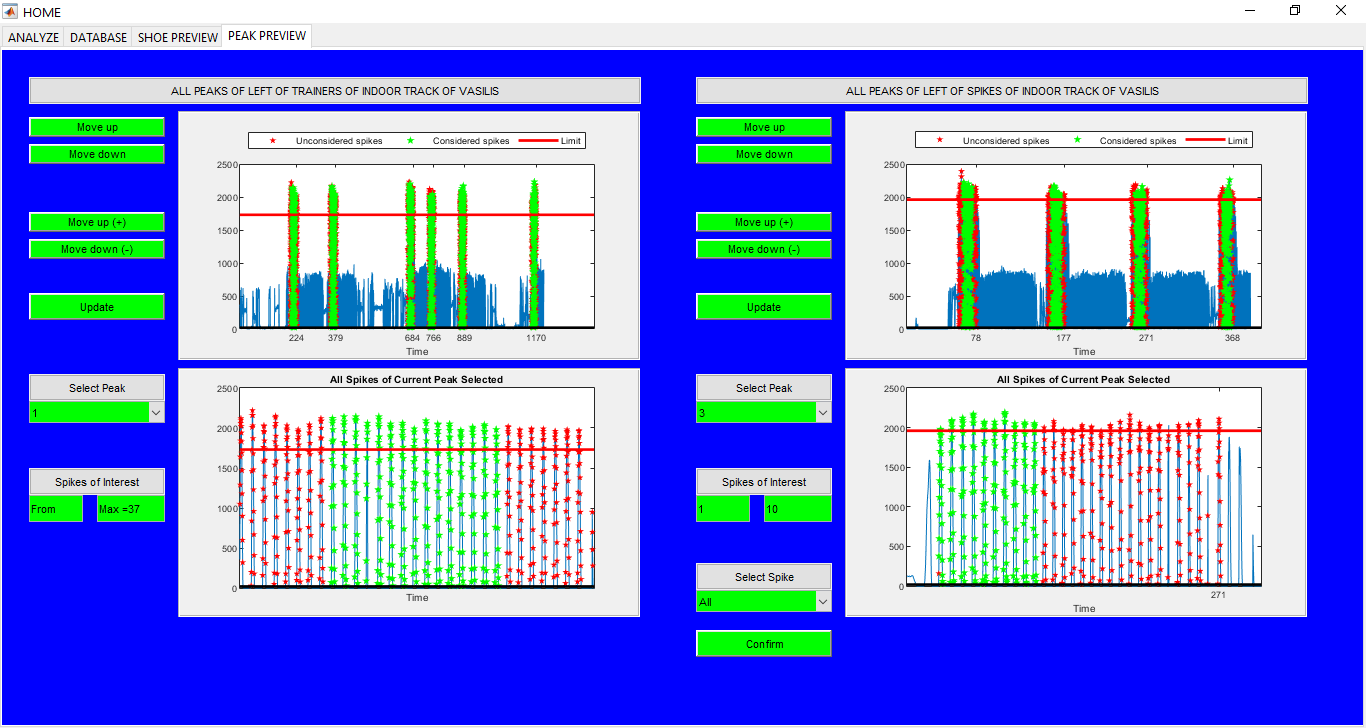
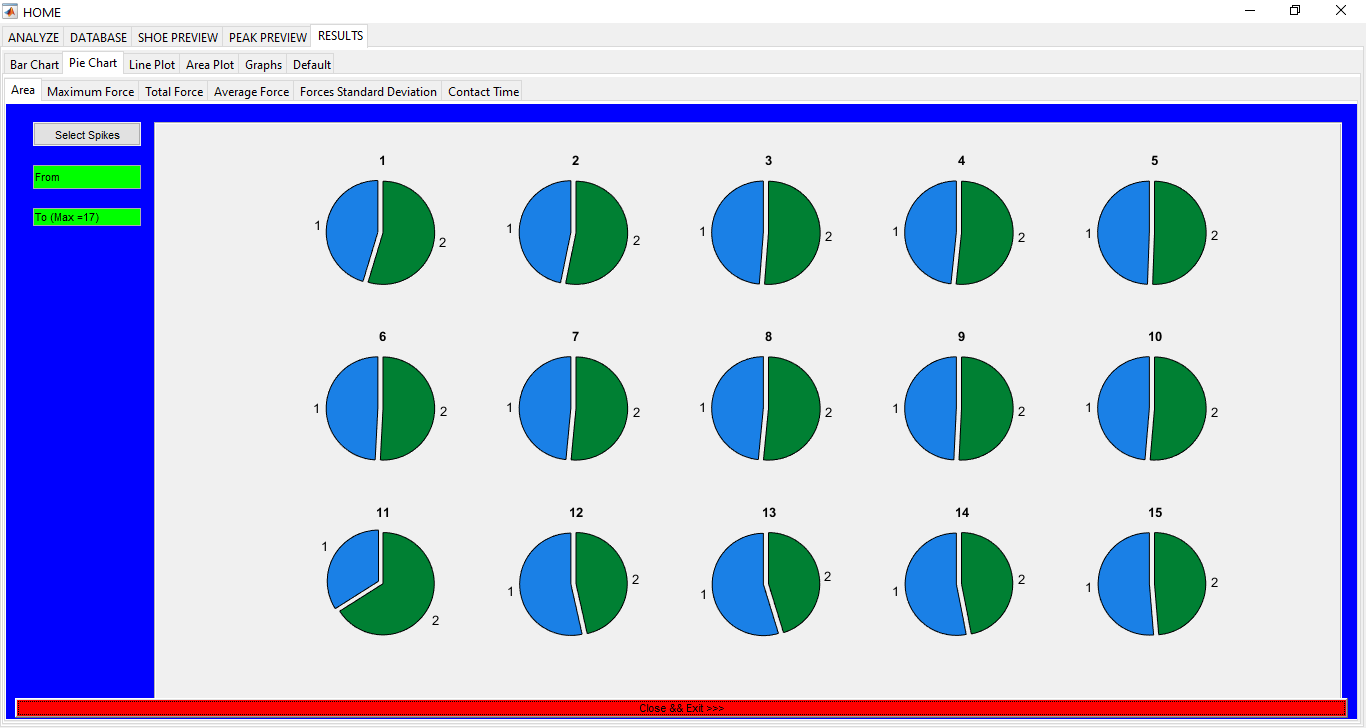
Sports Data Analytics Toolbox
An App for sports data analytics for different subjects running in different shoes and on different surfaces. Database for all the shoes, surfaces, and the subjects is kept as well. ** UNLESS UNDER SPECIAL CIRCUMSTANCES, THIS APP IS NOT AVAILABLE FOR DOWNLOAD **
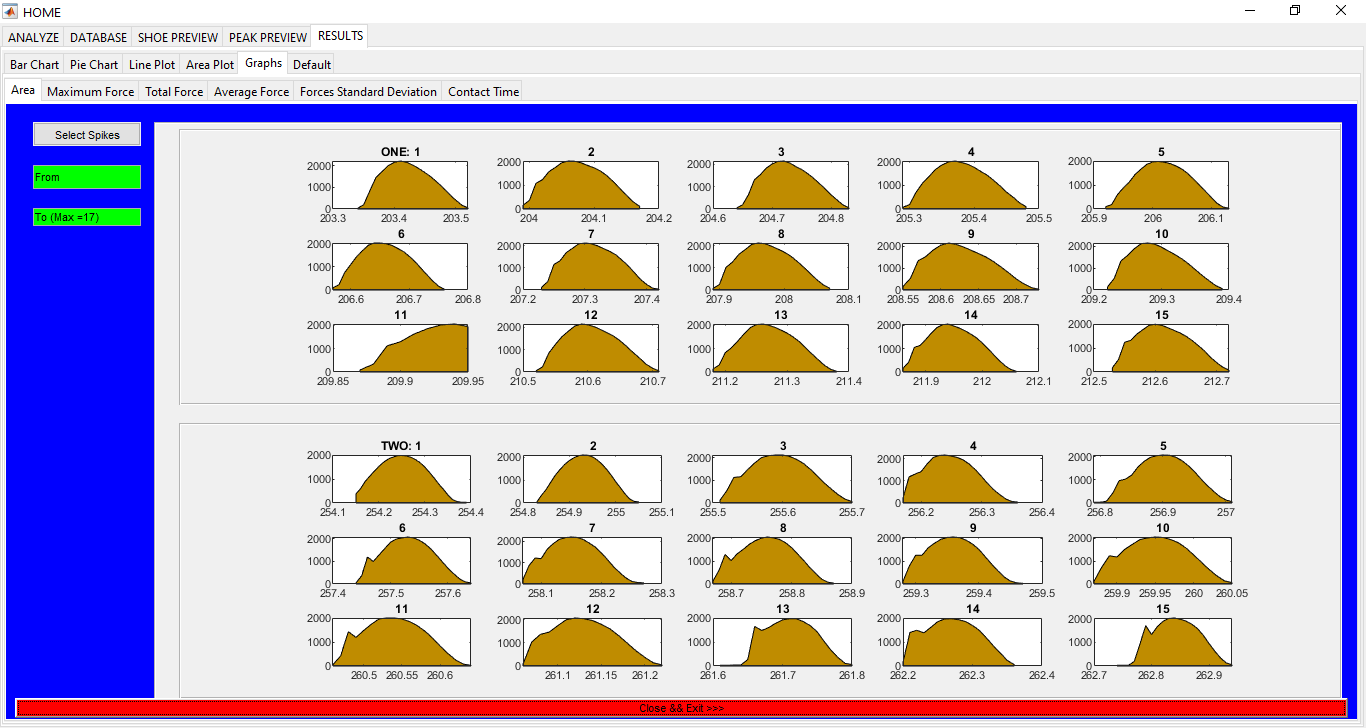
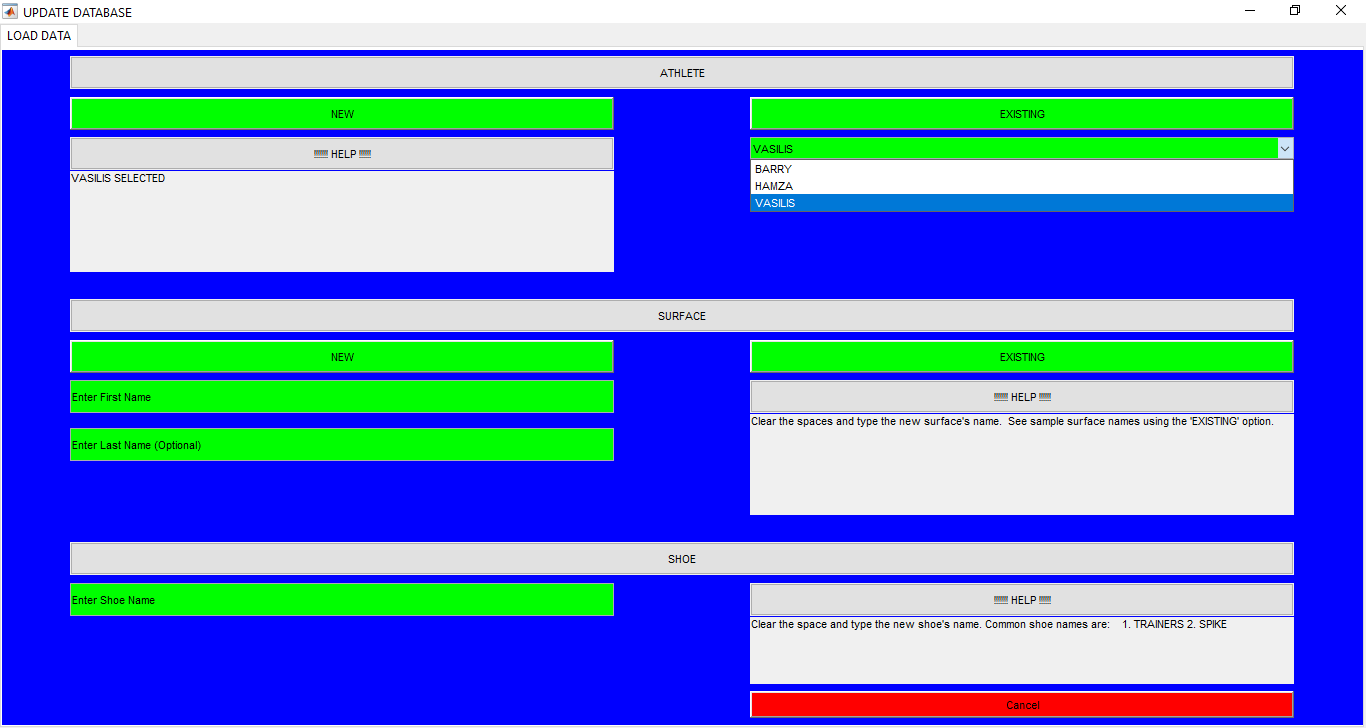
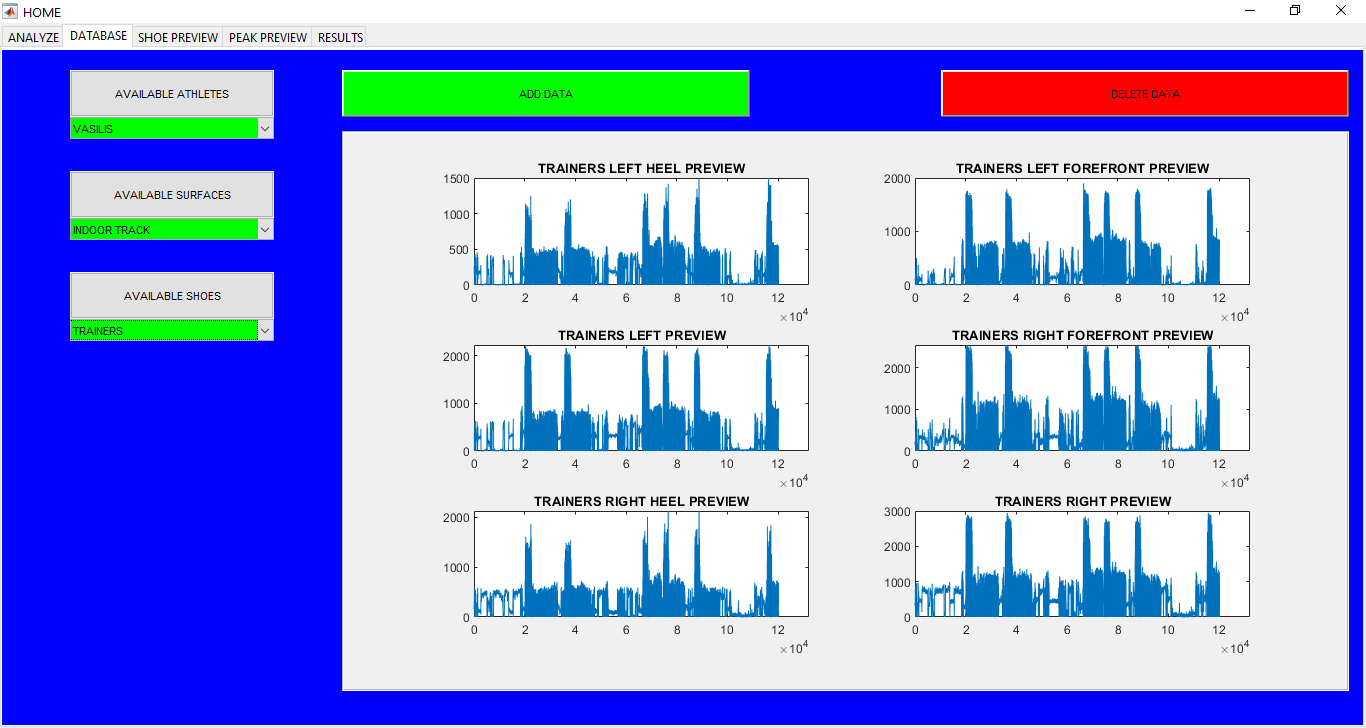
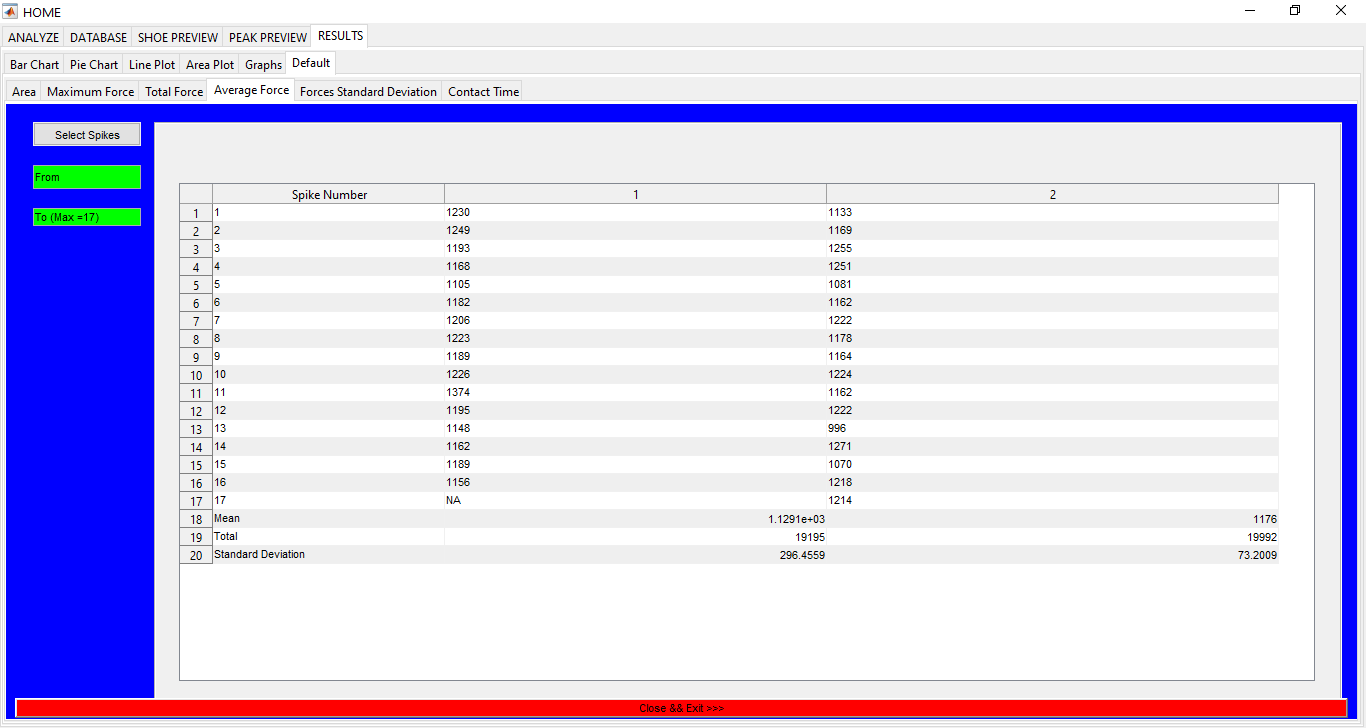
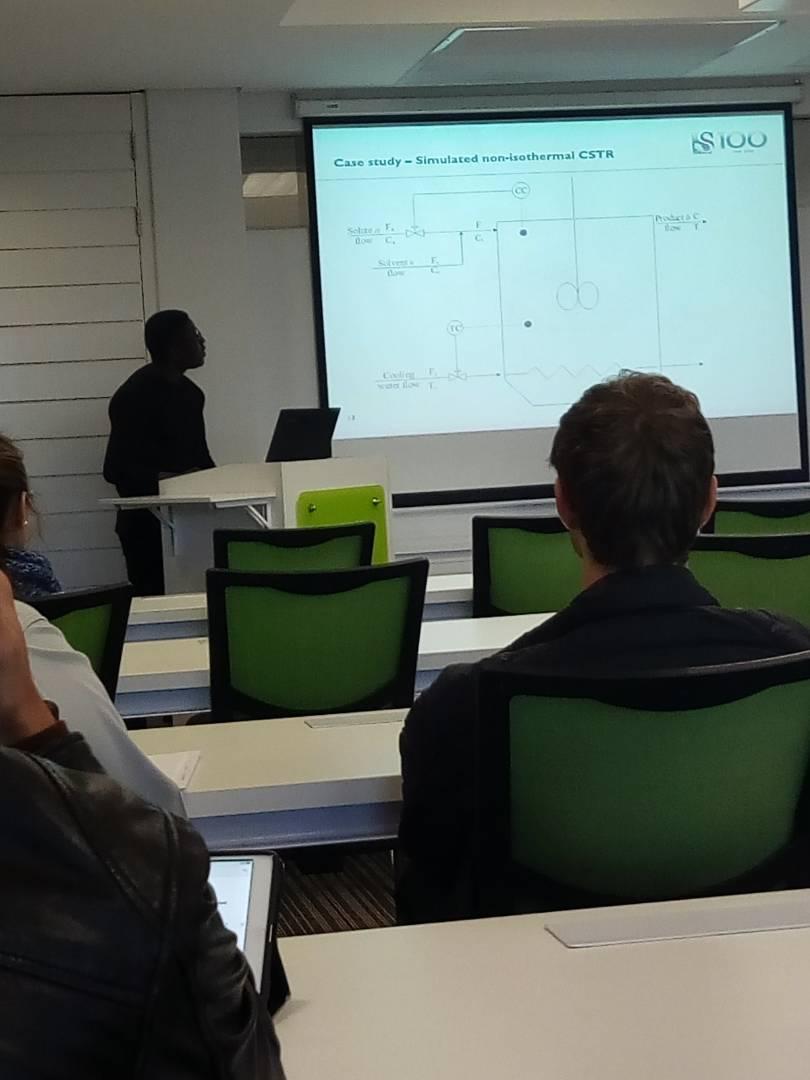
This work builds a Simulink model and a MATLAB program that uses graphical user interfaces (GUI) for simulating the Non-isothermal CSTR which was first developed by Yoon and MacGregor (2001) in fault detection. The model incorporates different works of the non-isothermal CSTR into a combined model that simulates a unimodal/multimodal operation data and different process faults as well as closed/open loop operation.
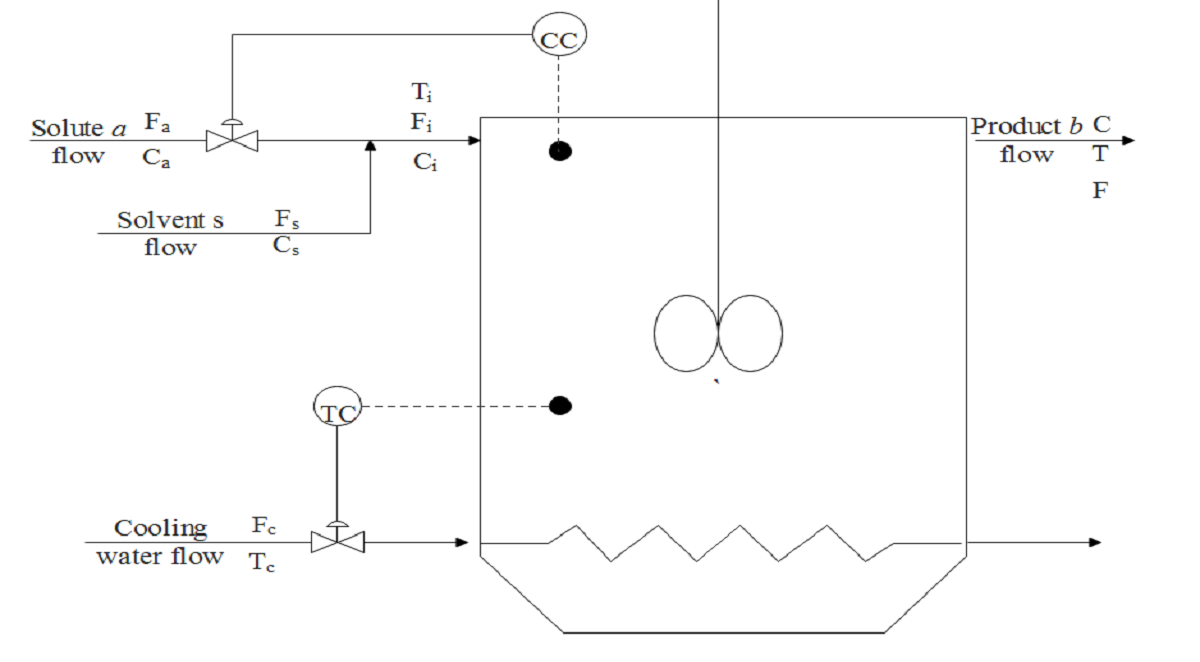
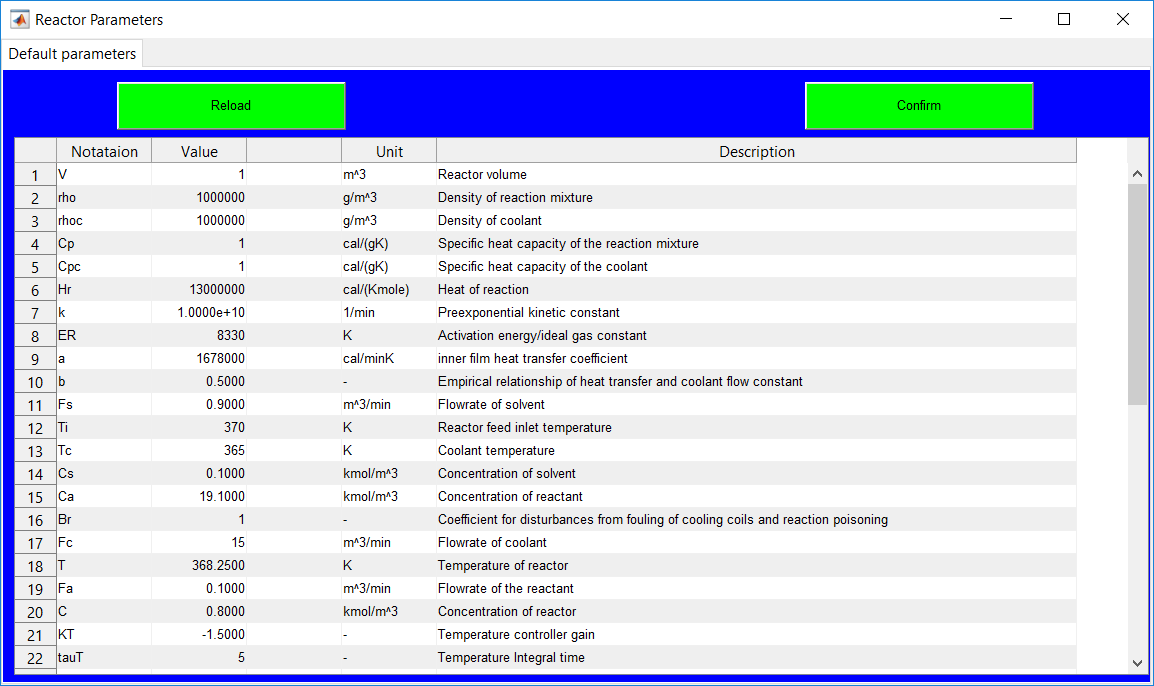
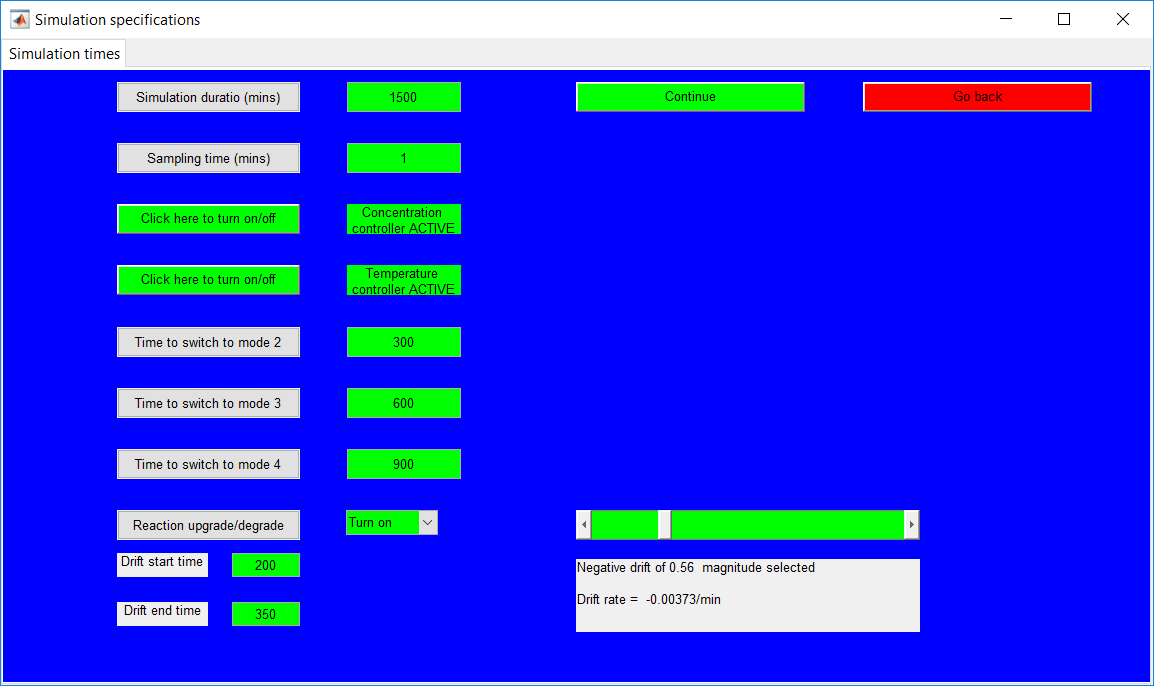
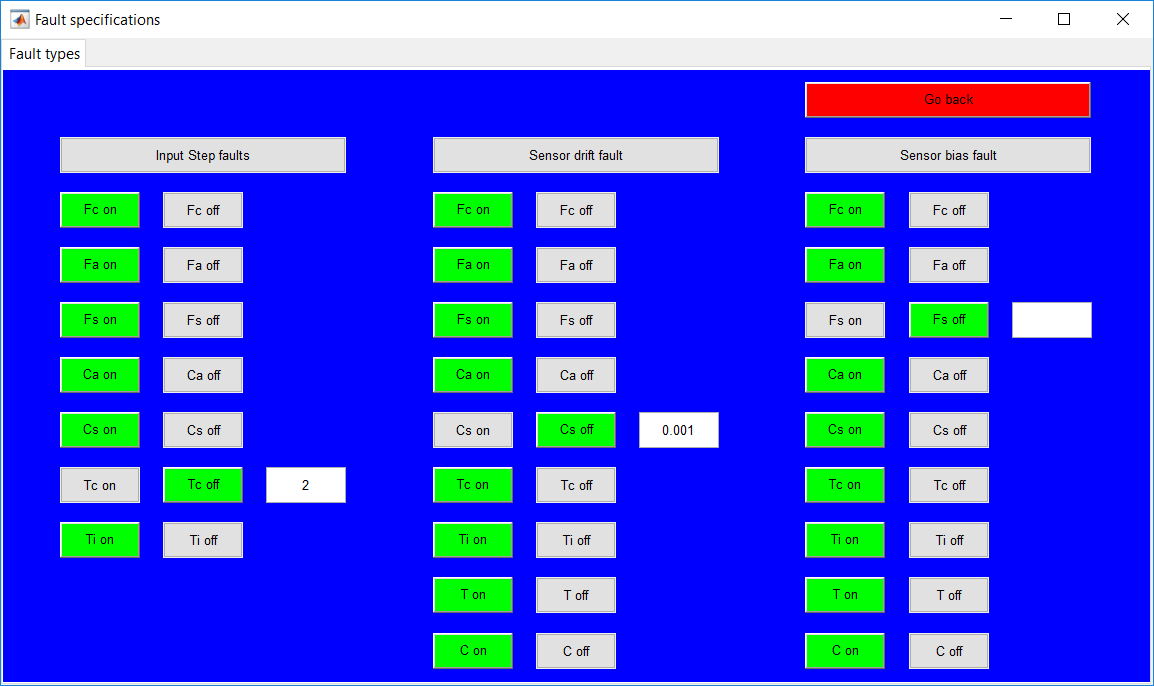
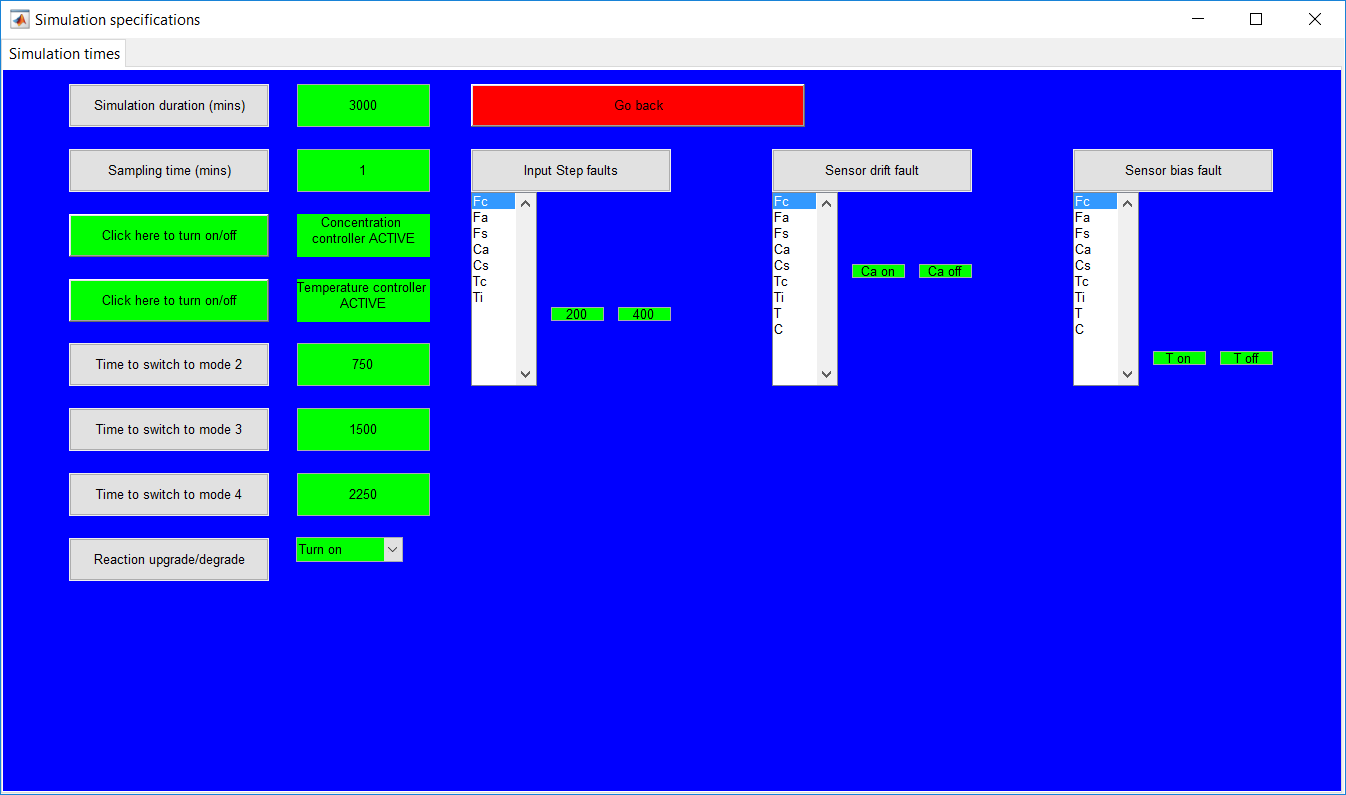
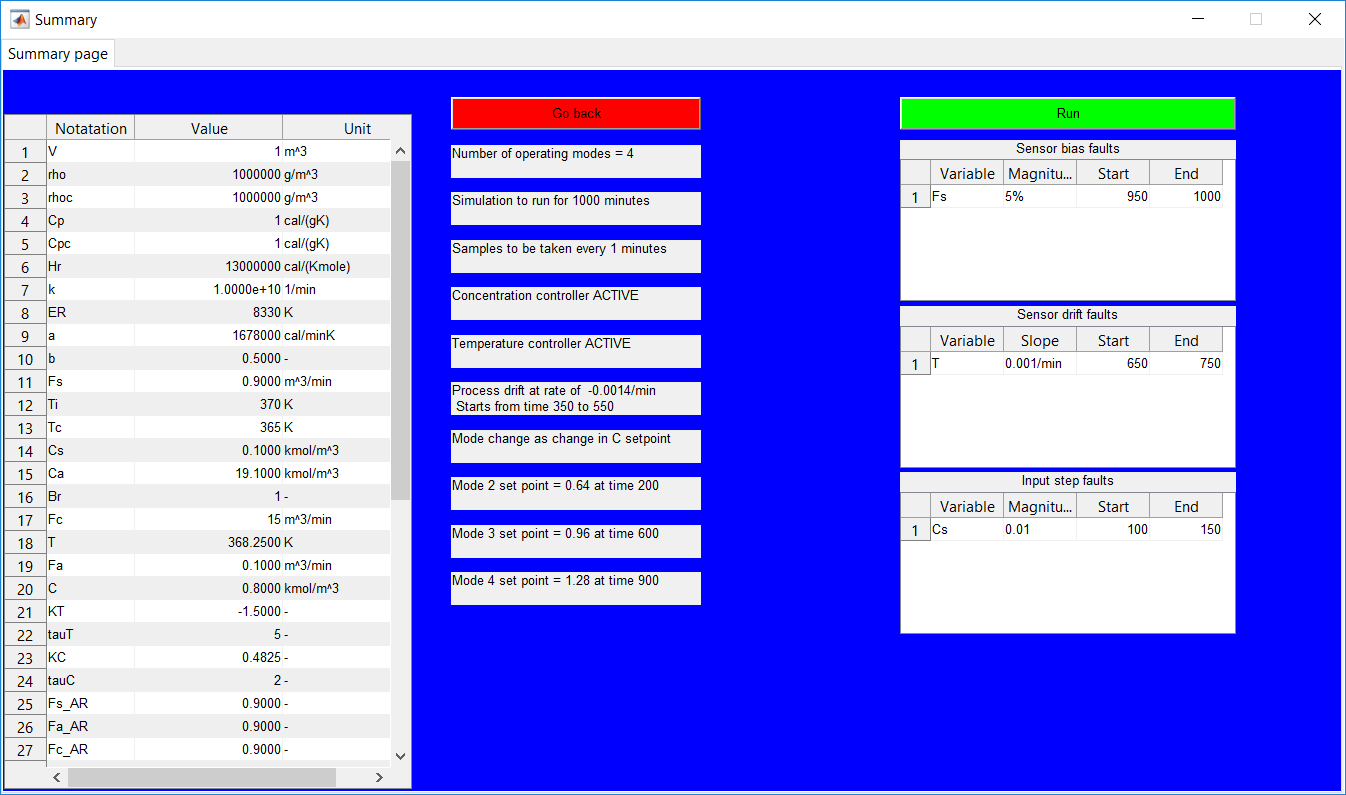
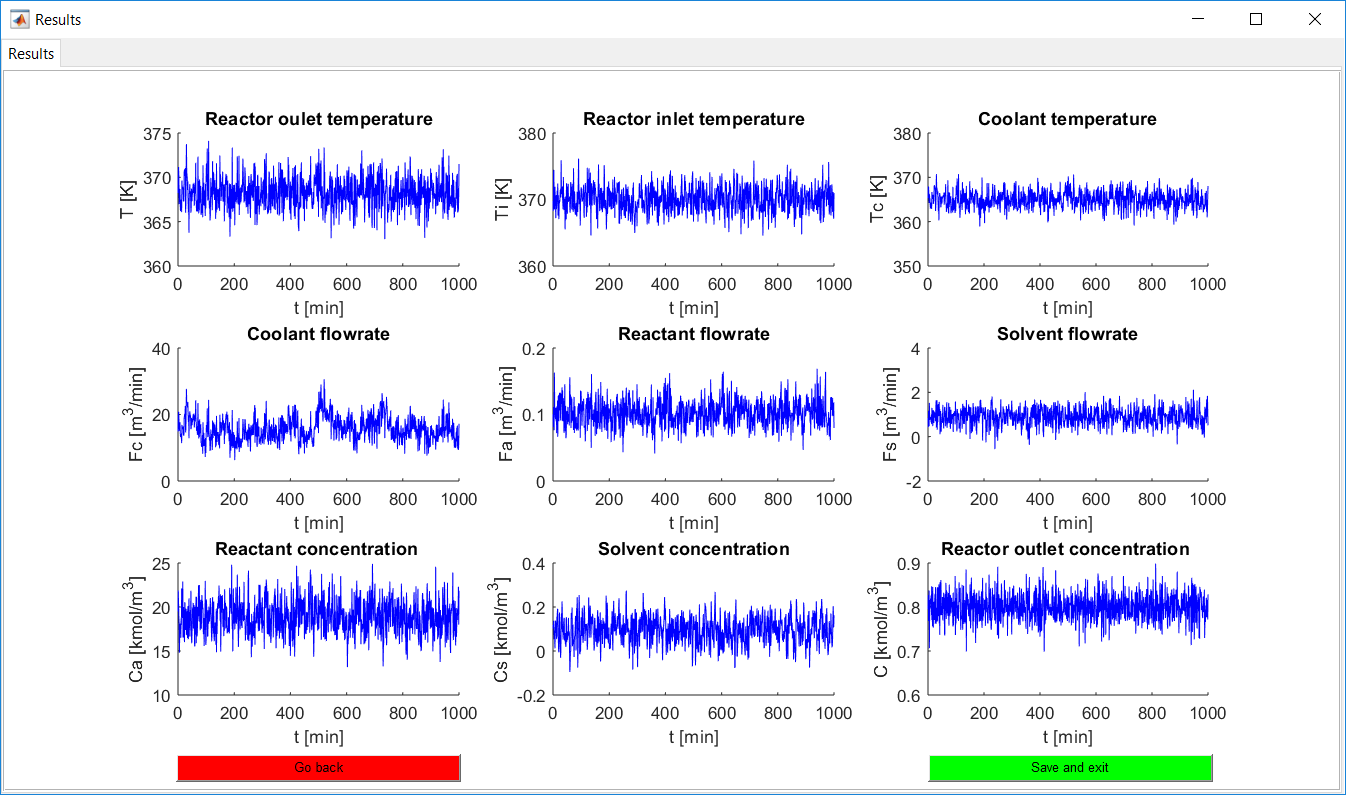
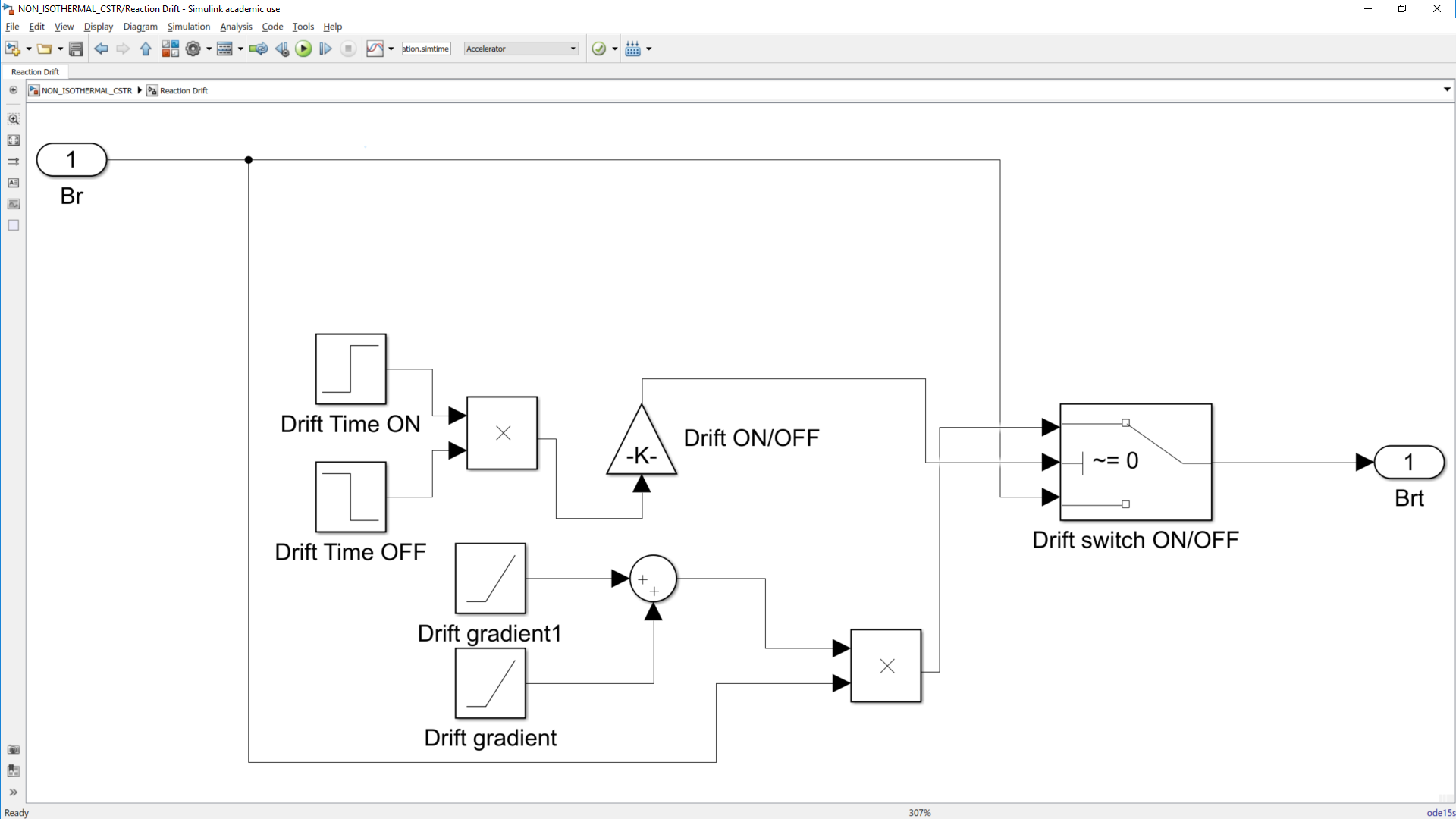
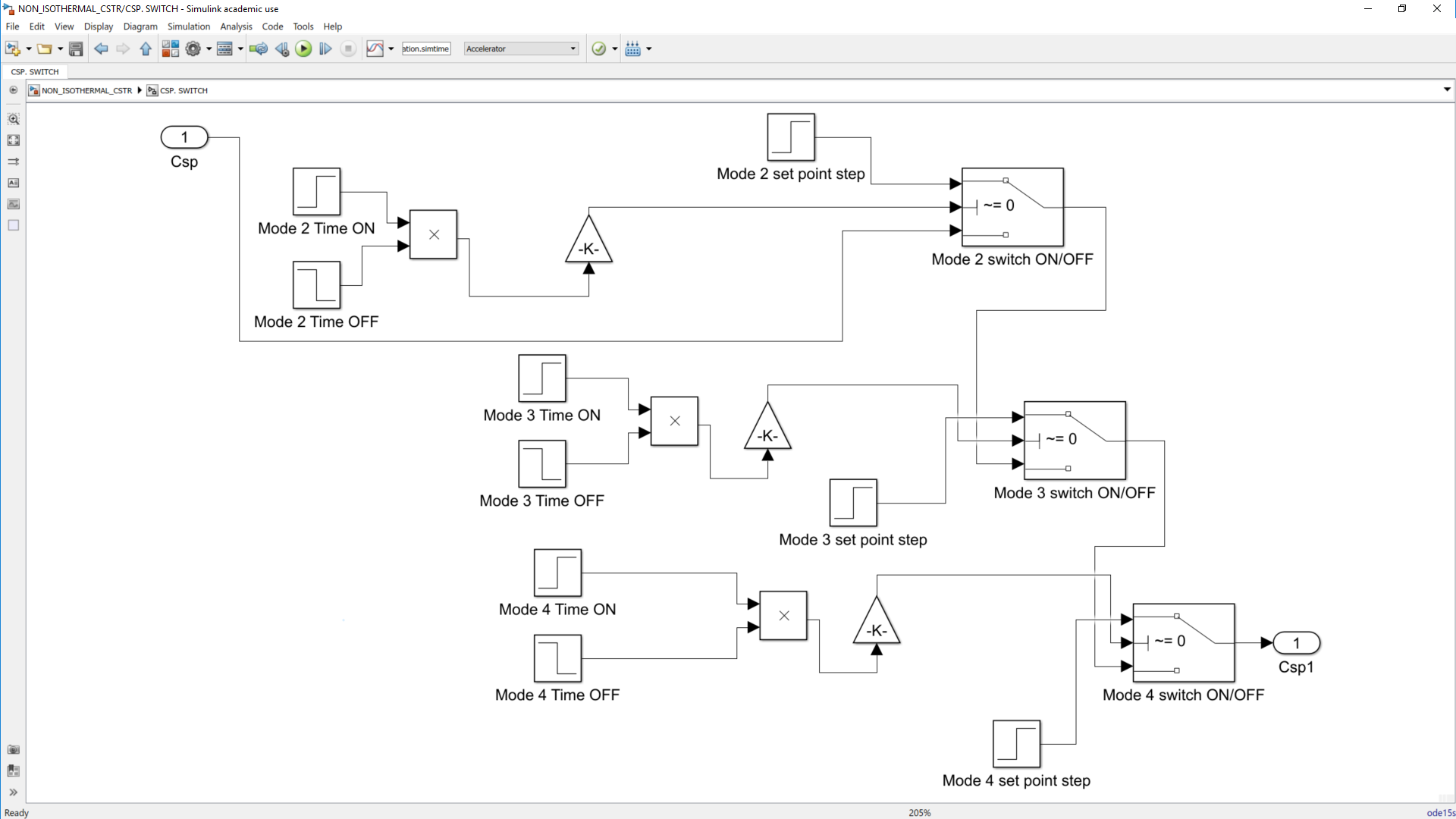
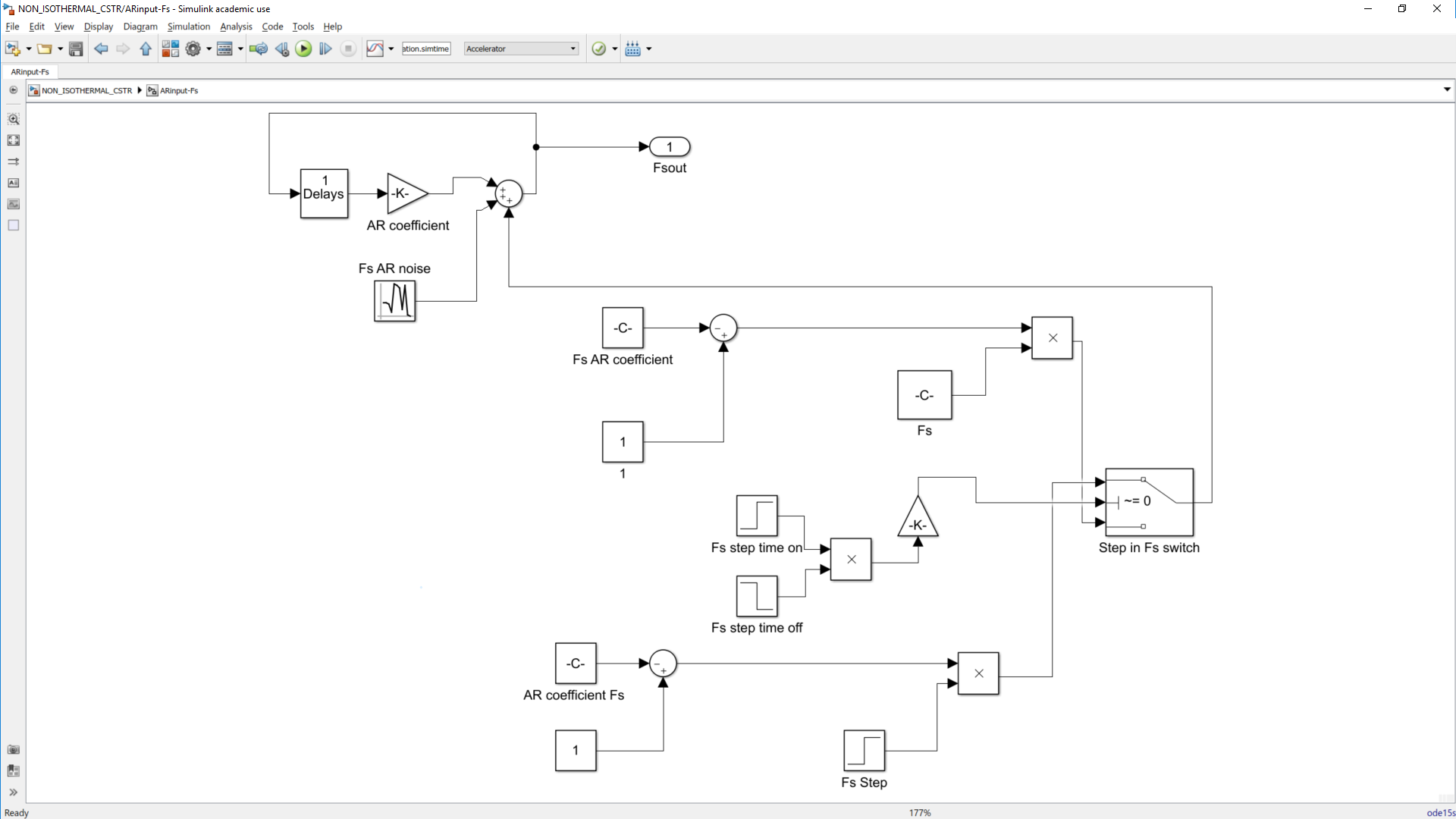
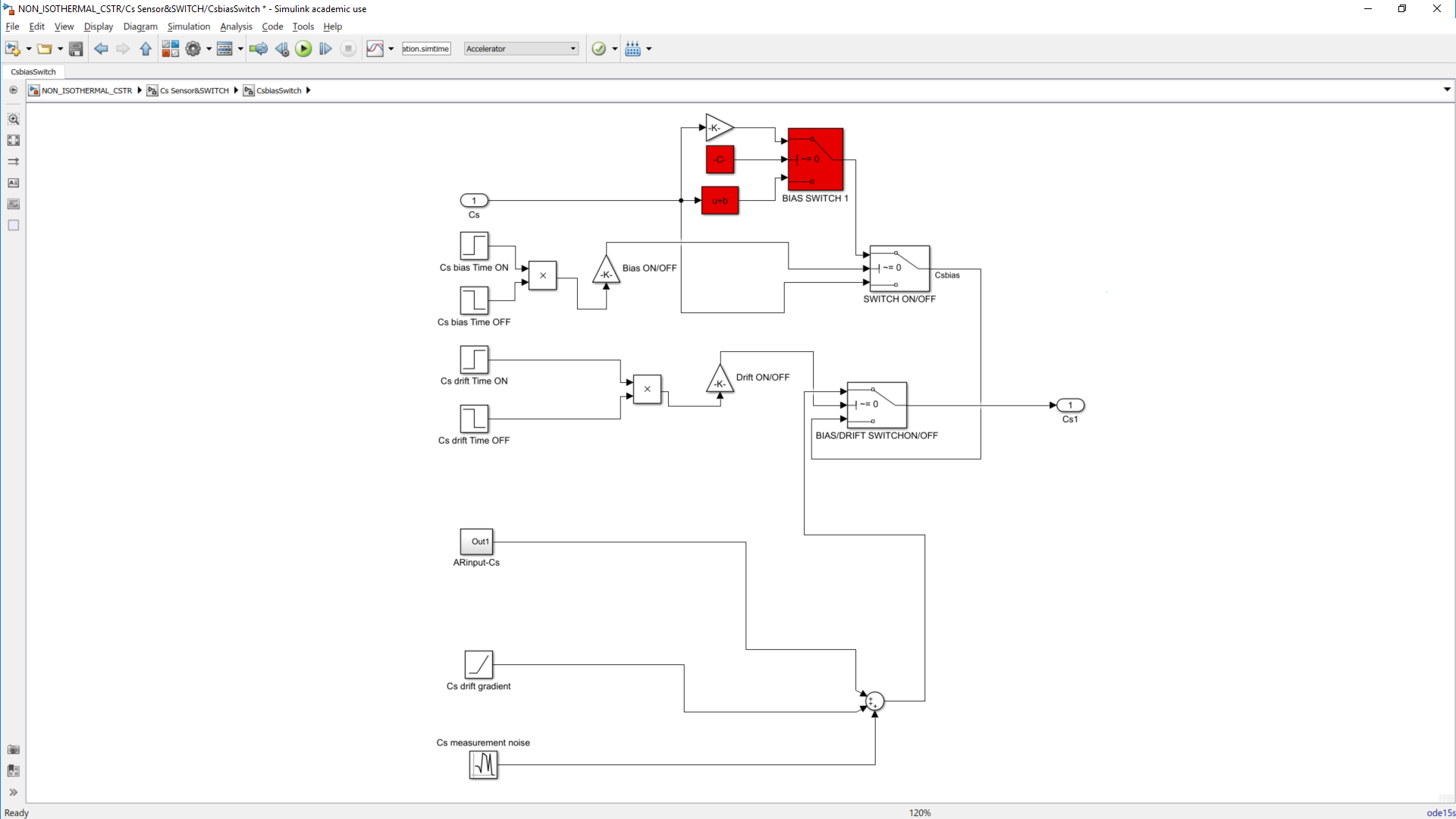
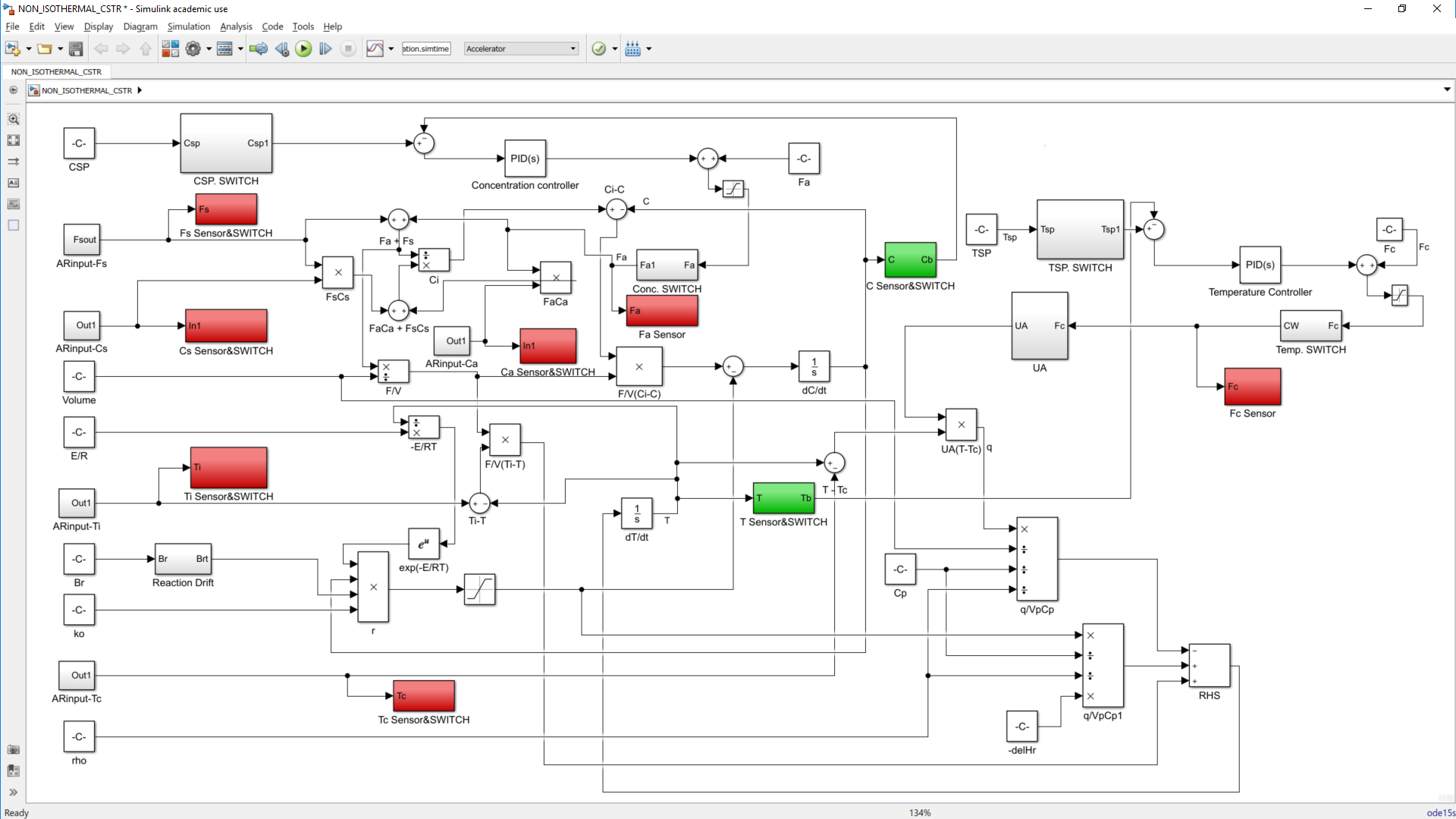
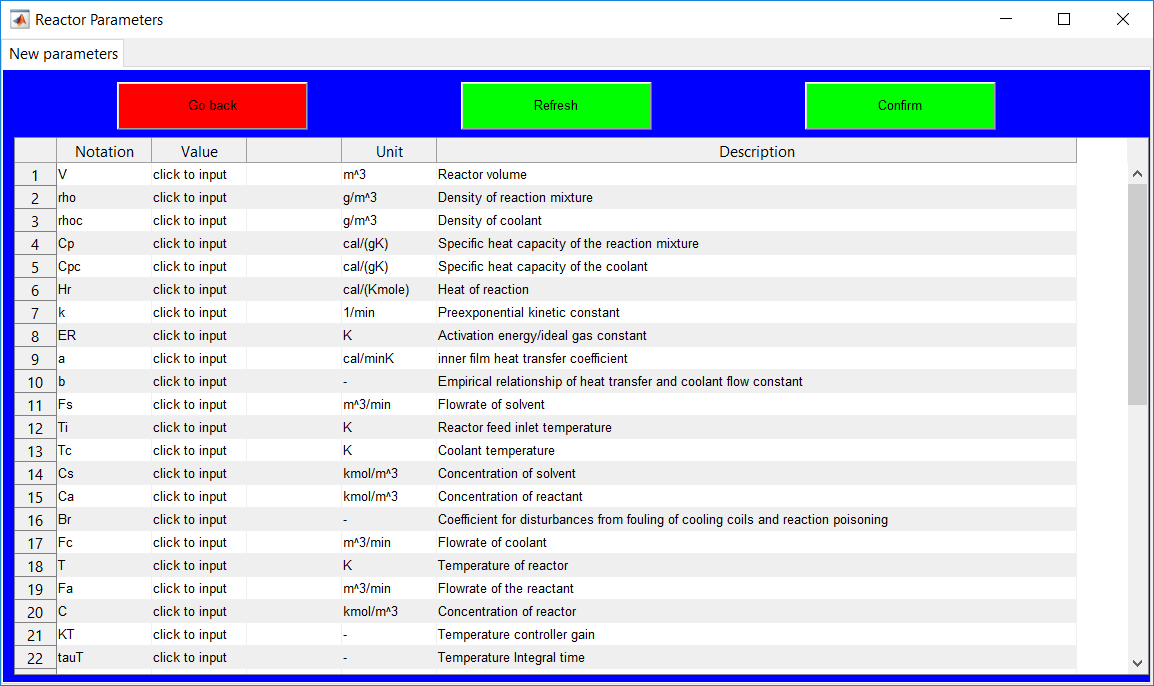
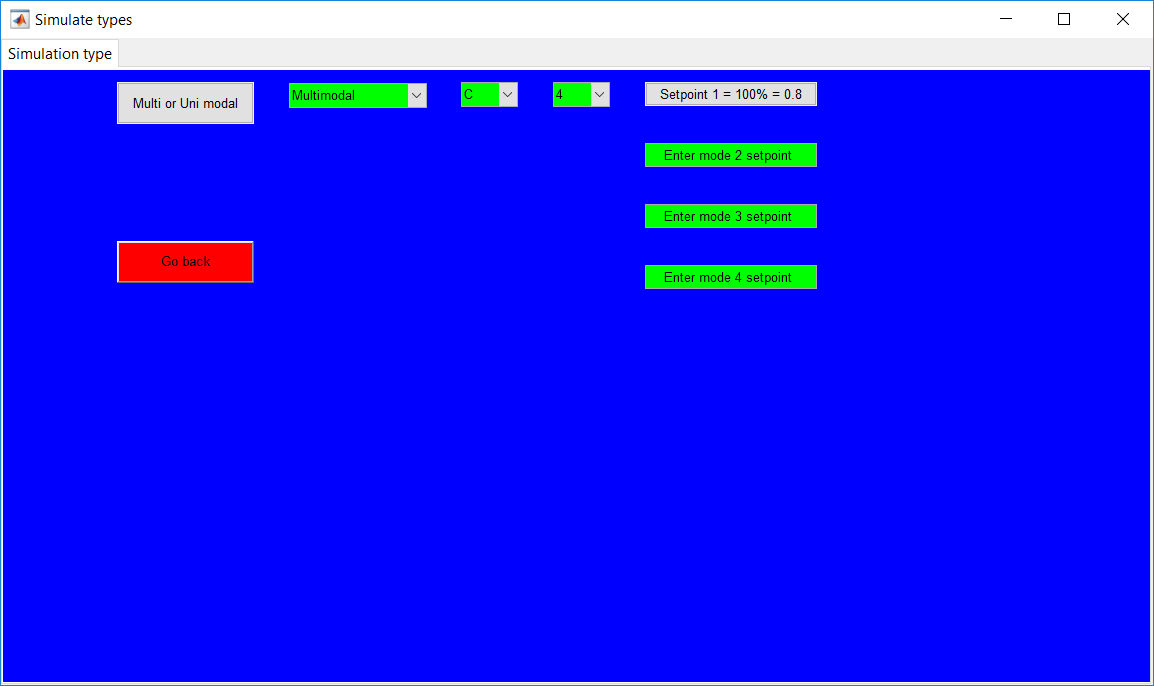
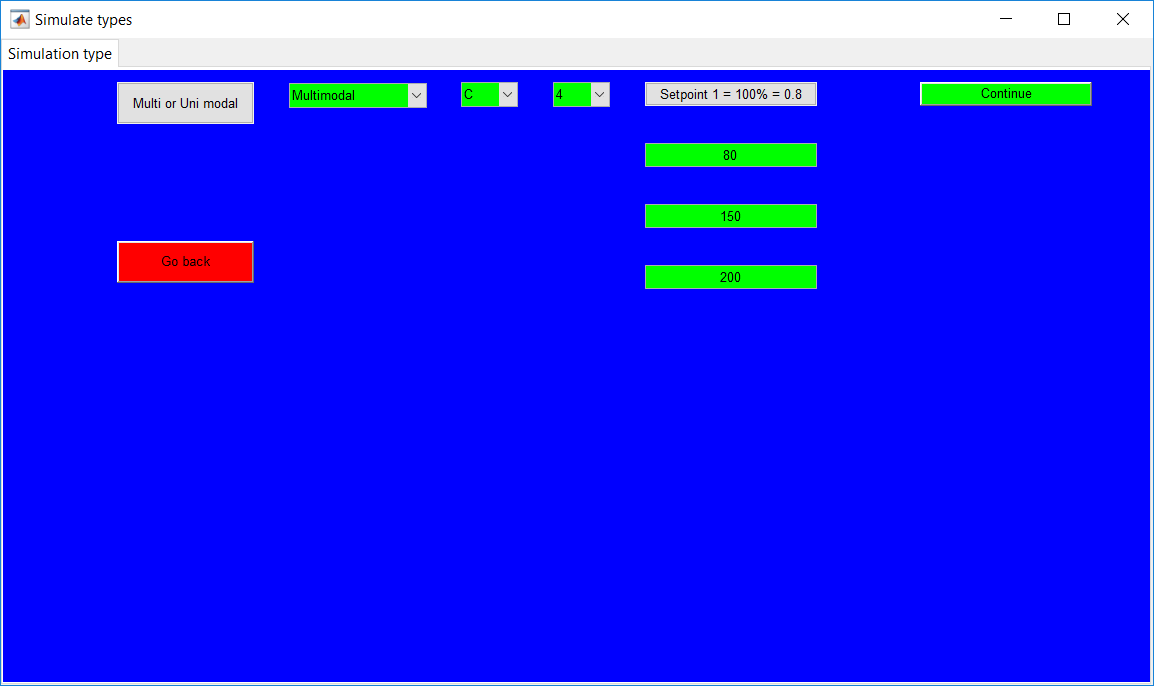
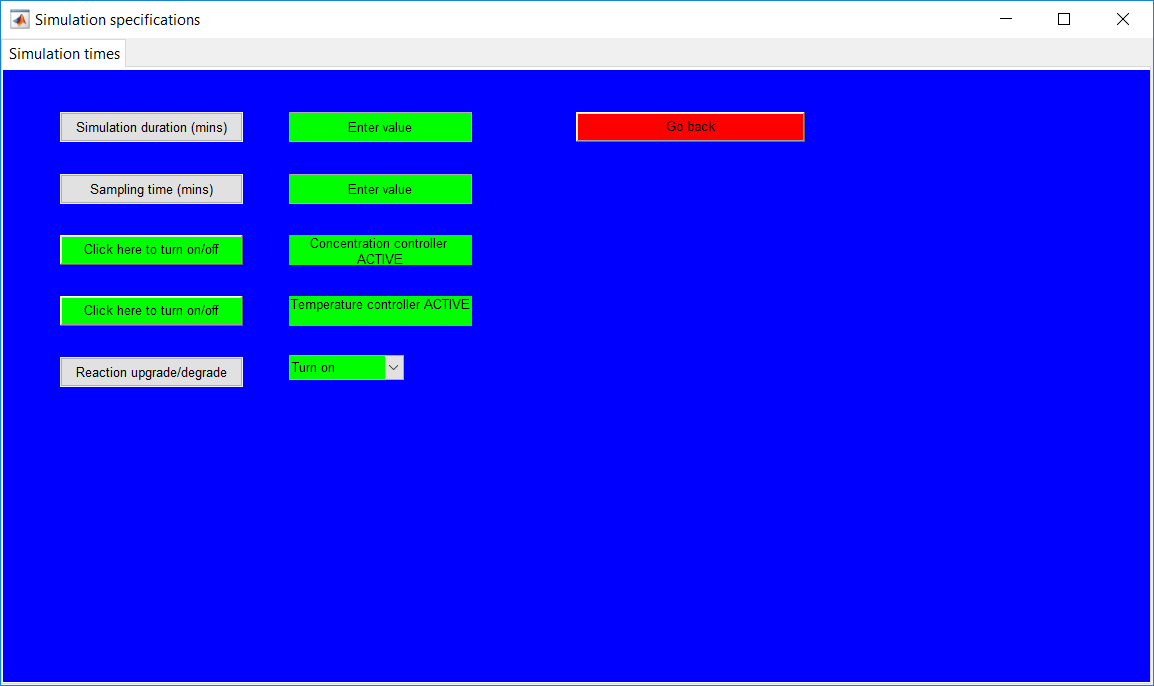
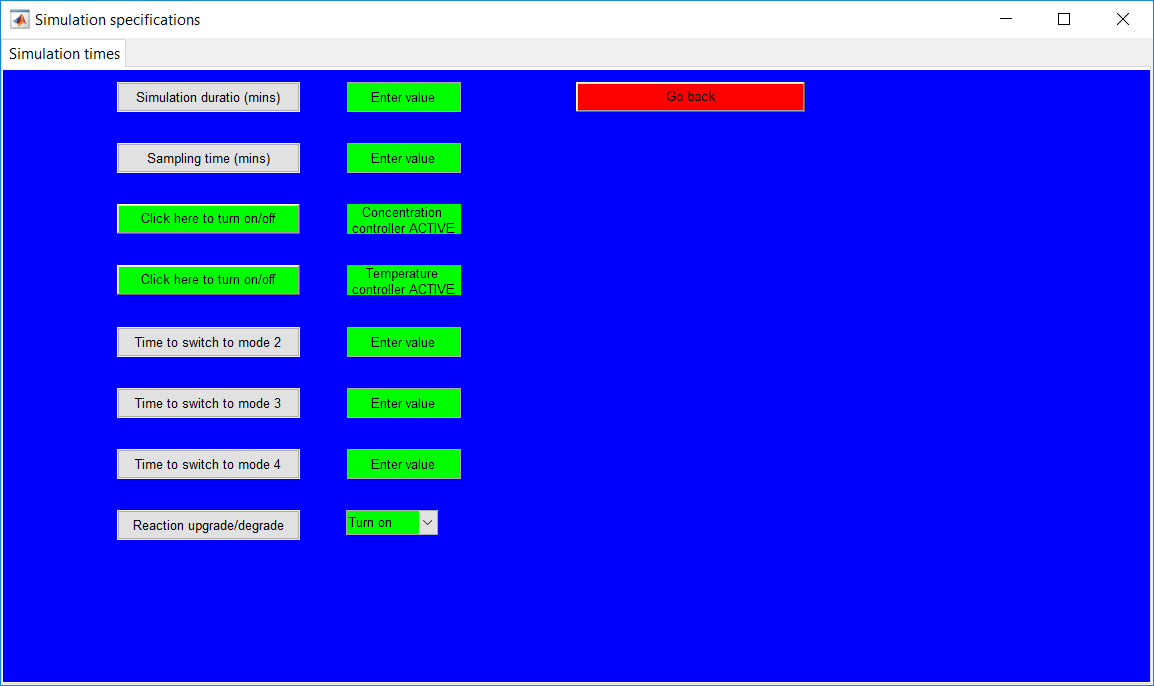
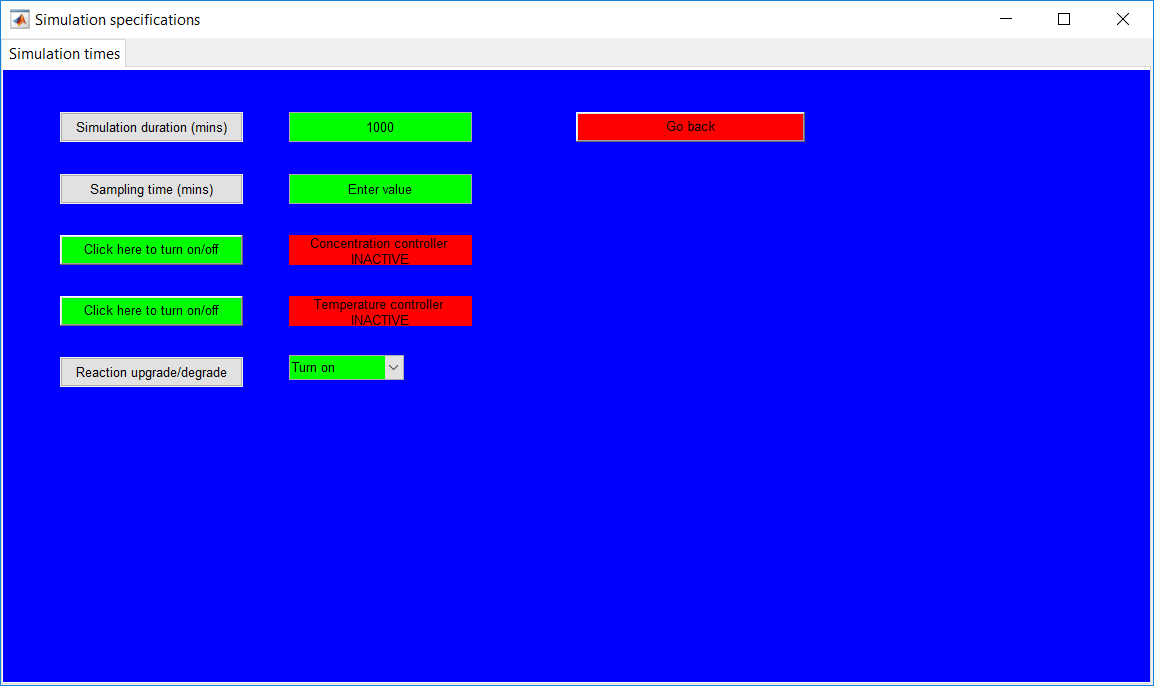
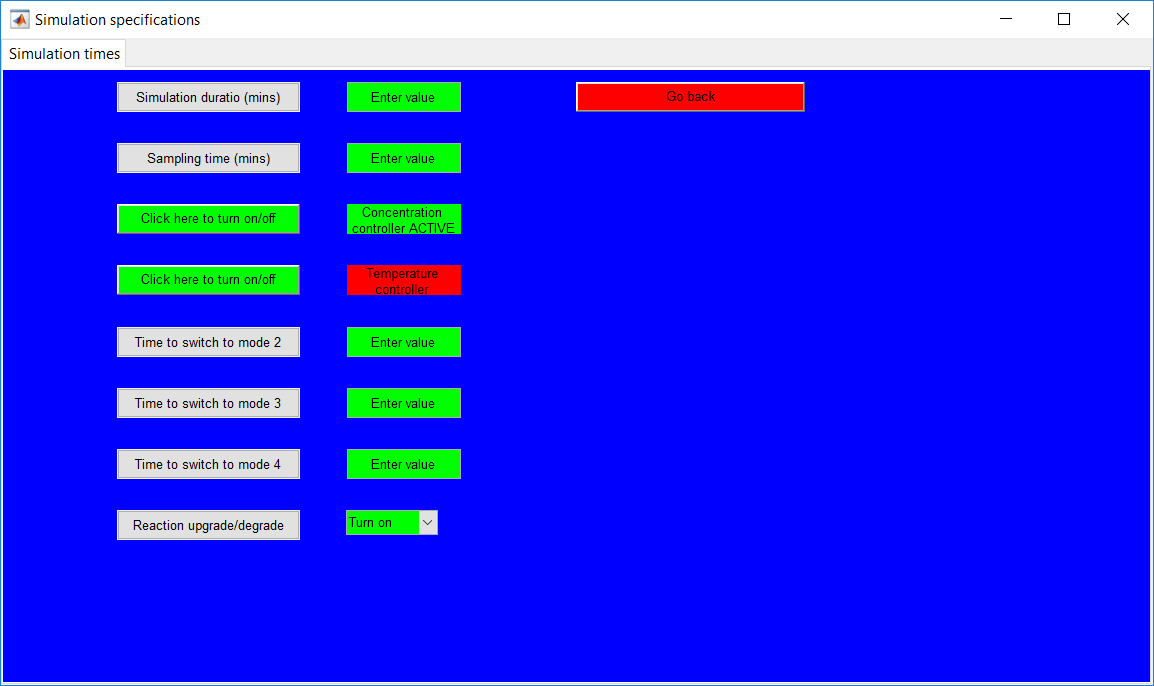
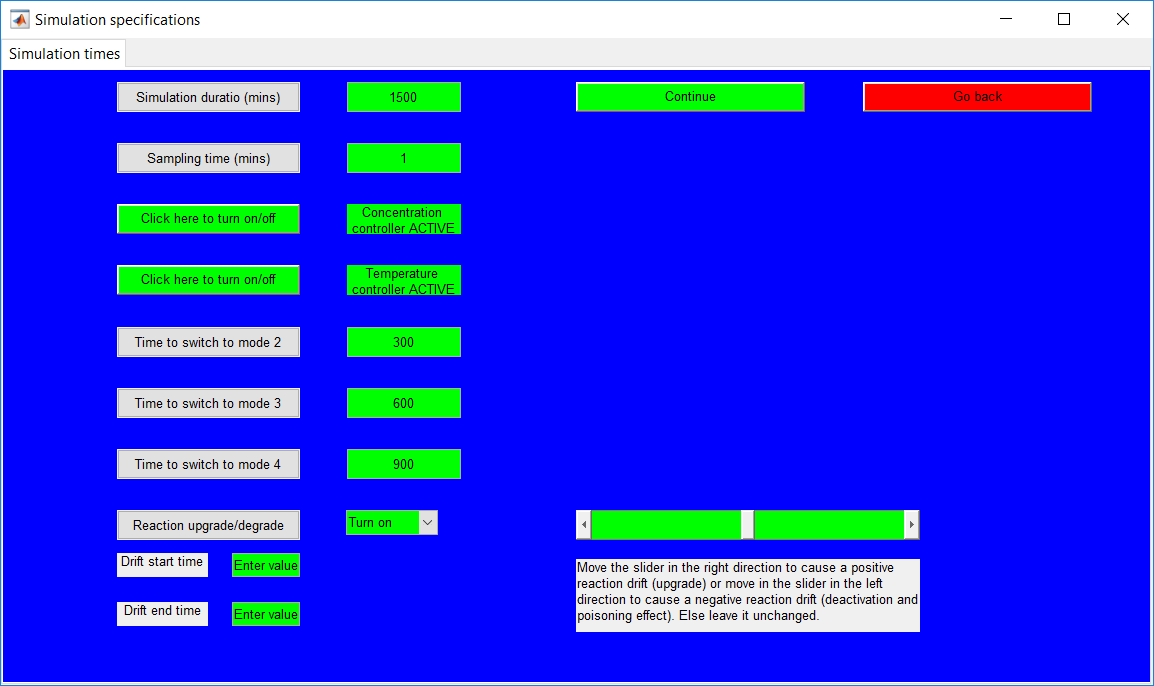
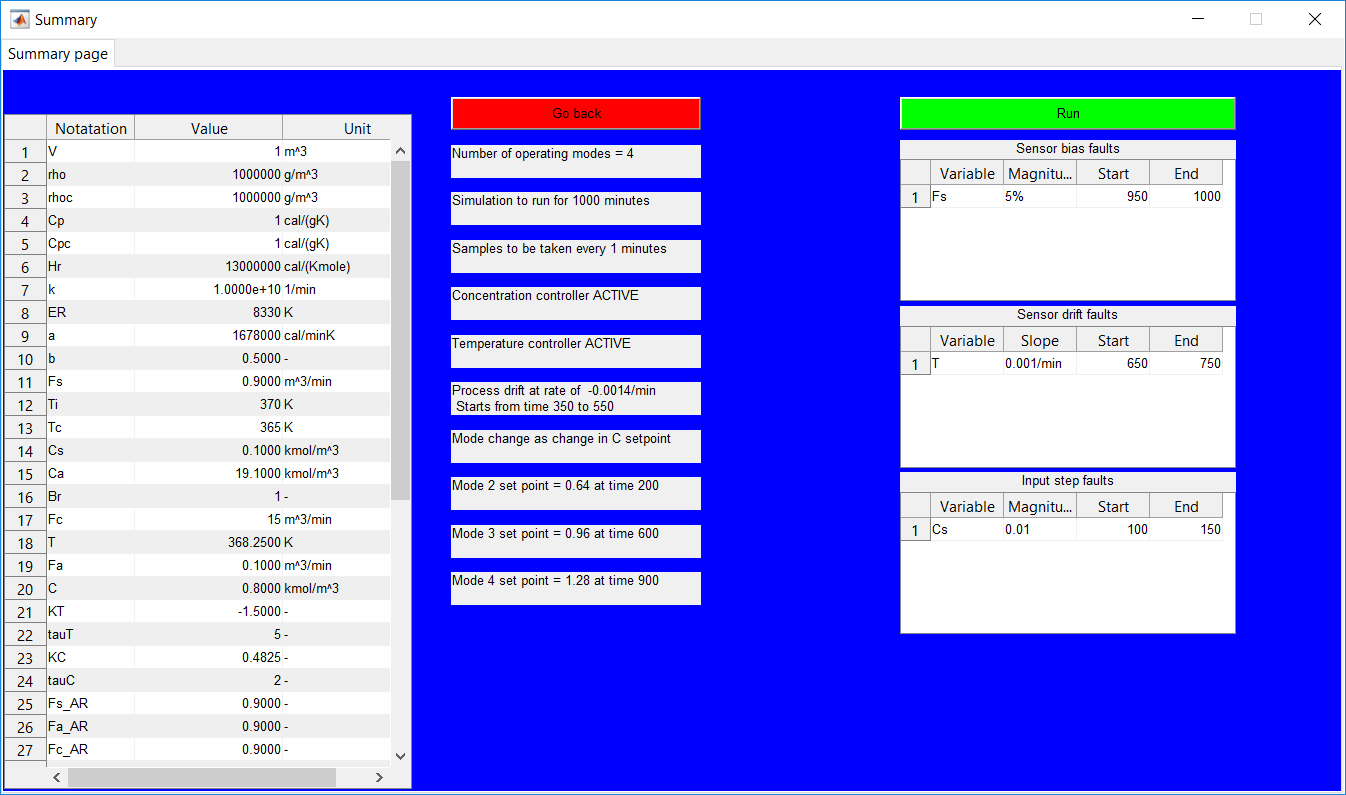
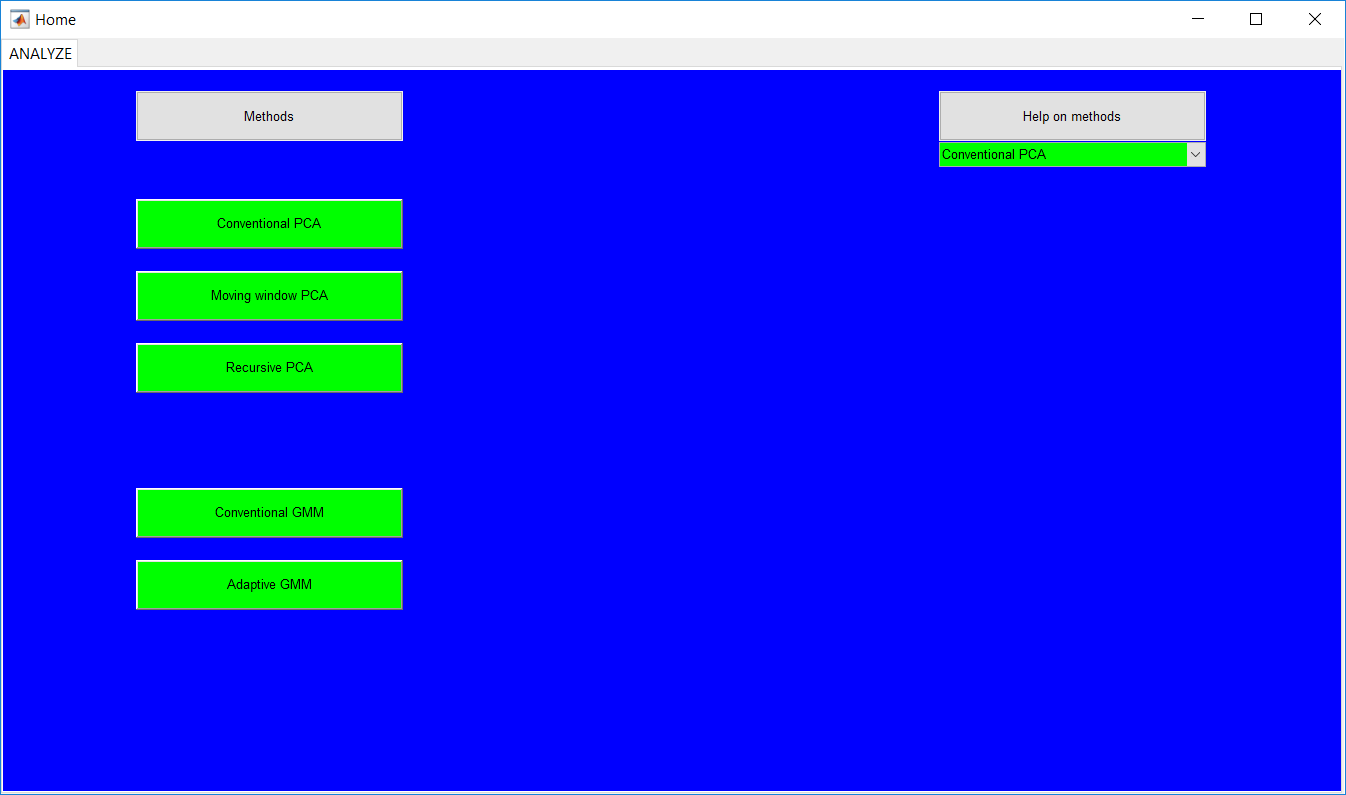
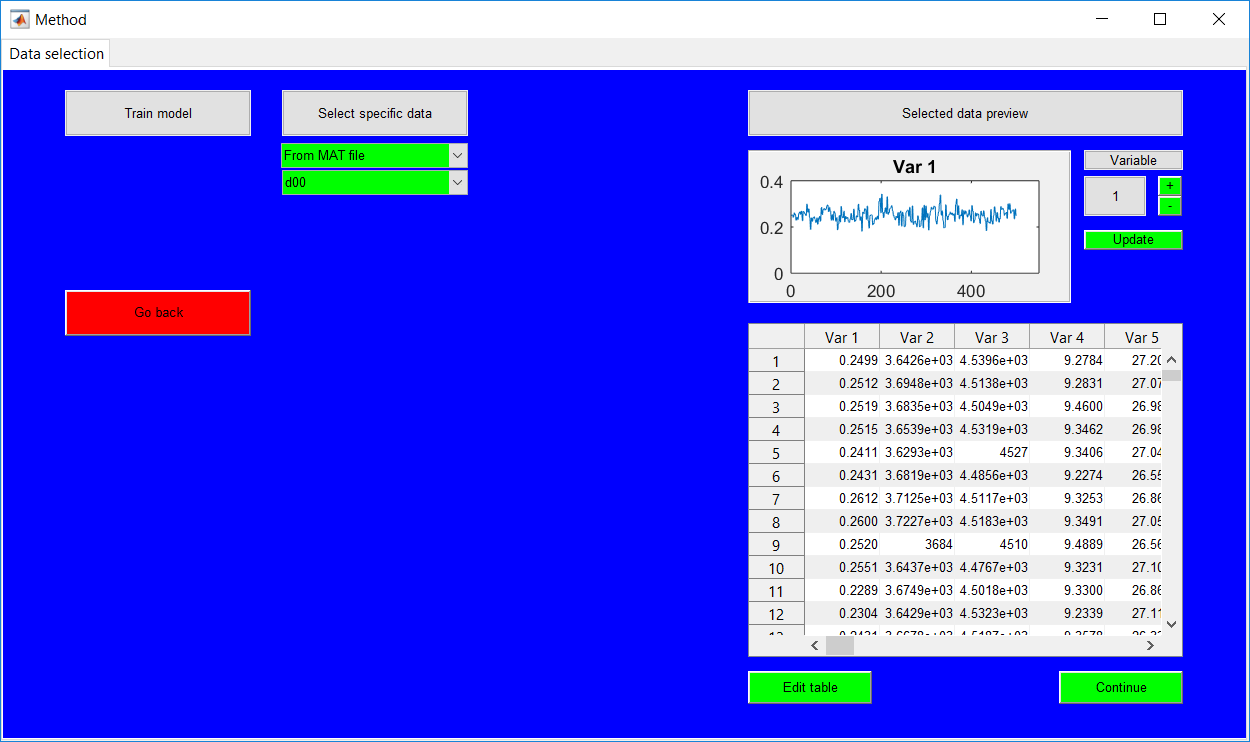
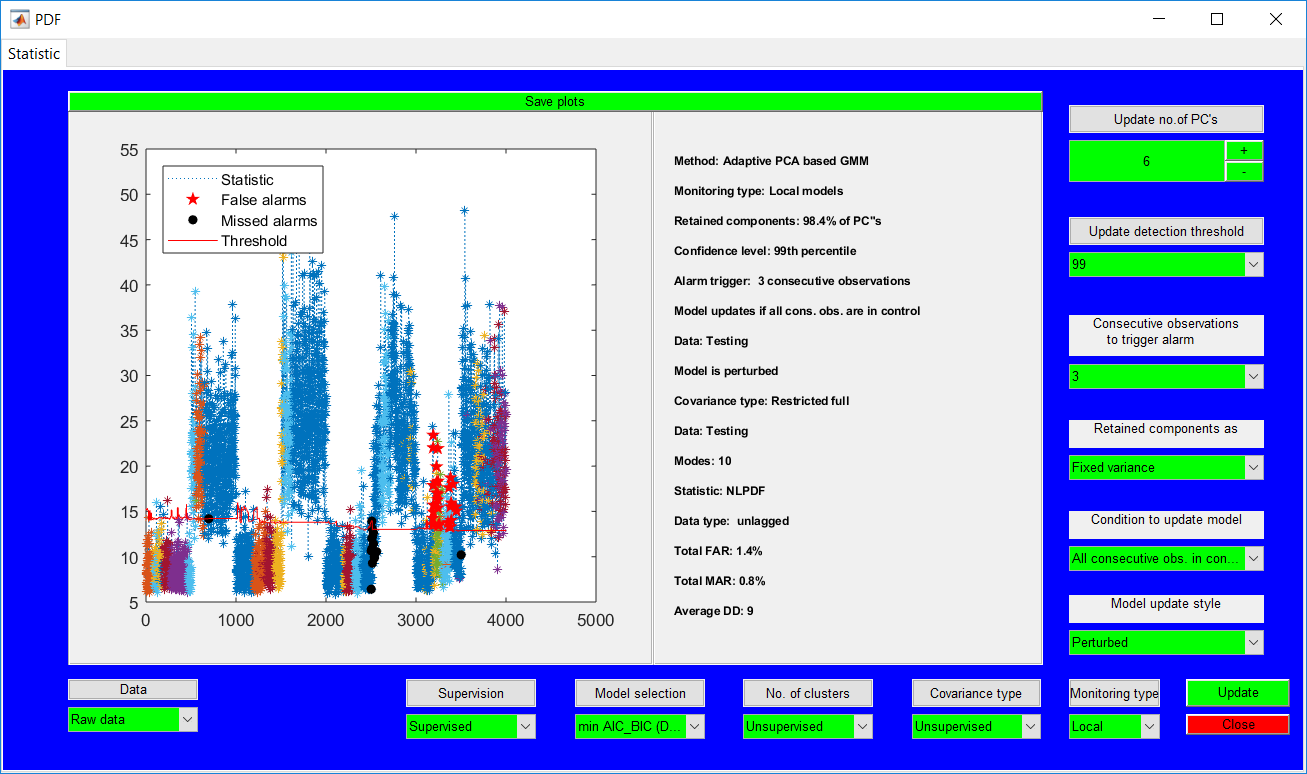
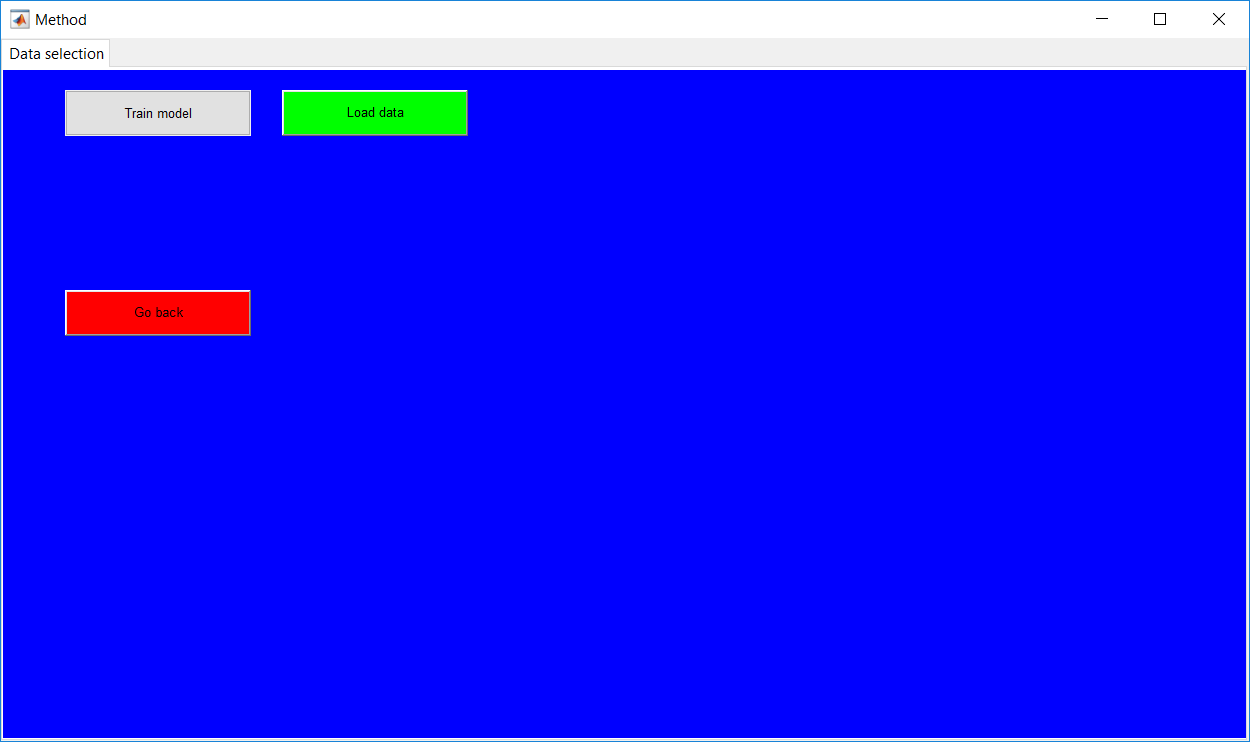
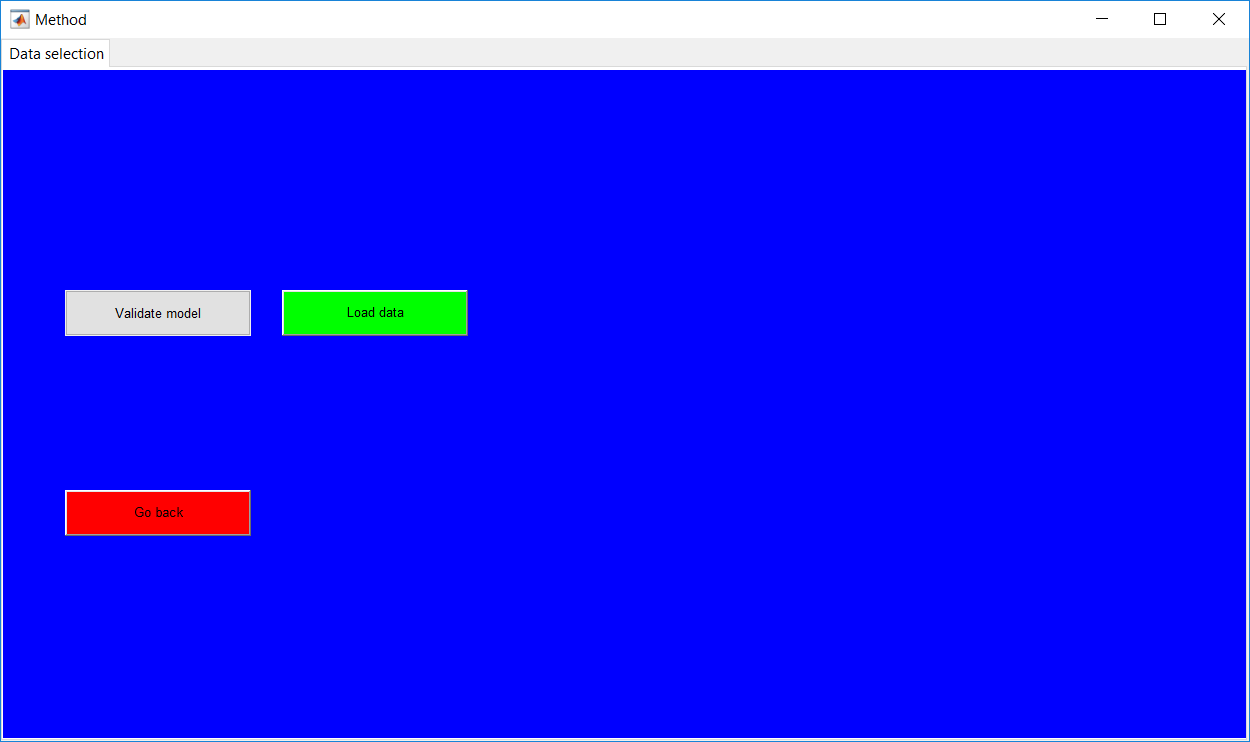
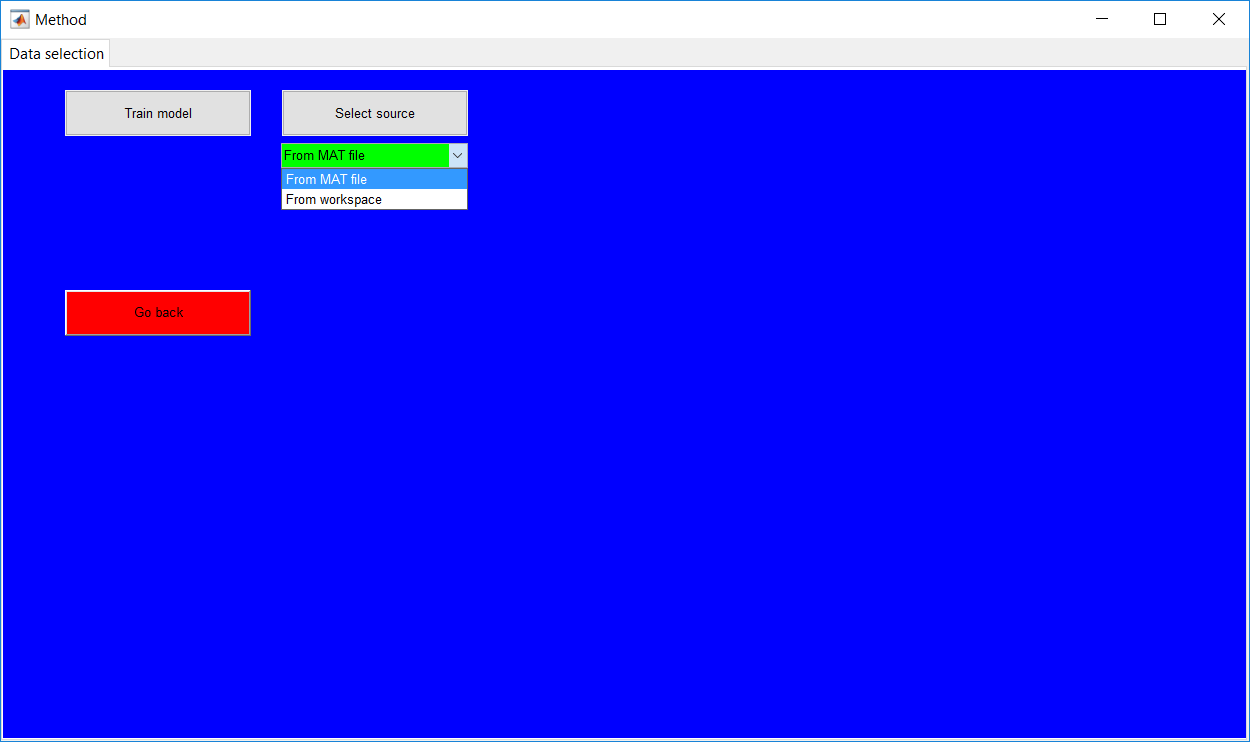
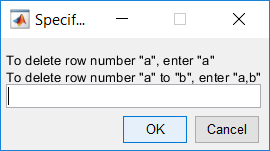
Process Monitoring Toolbox
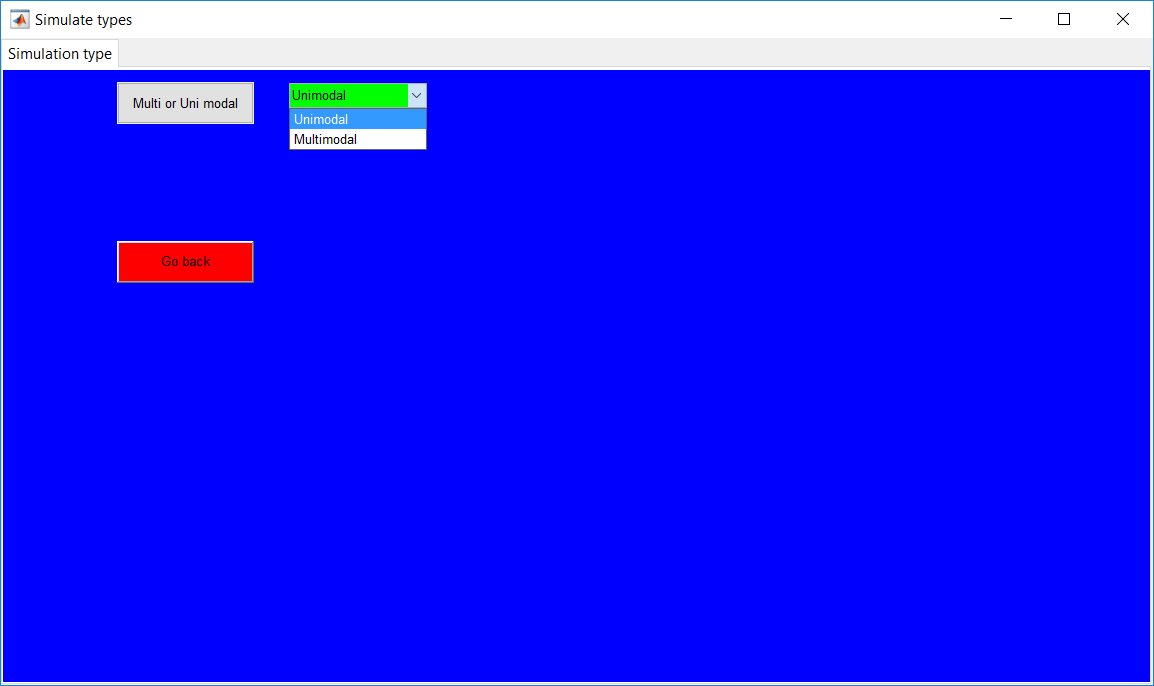
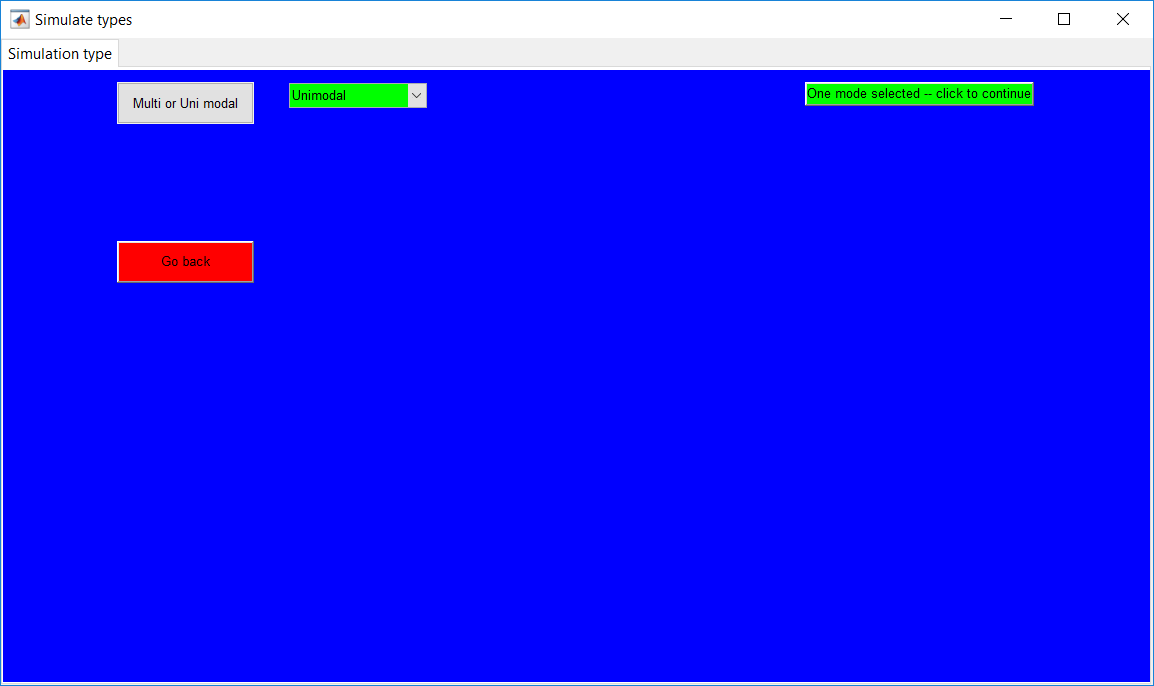
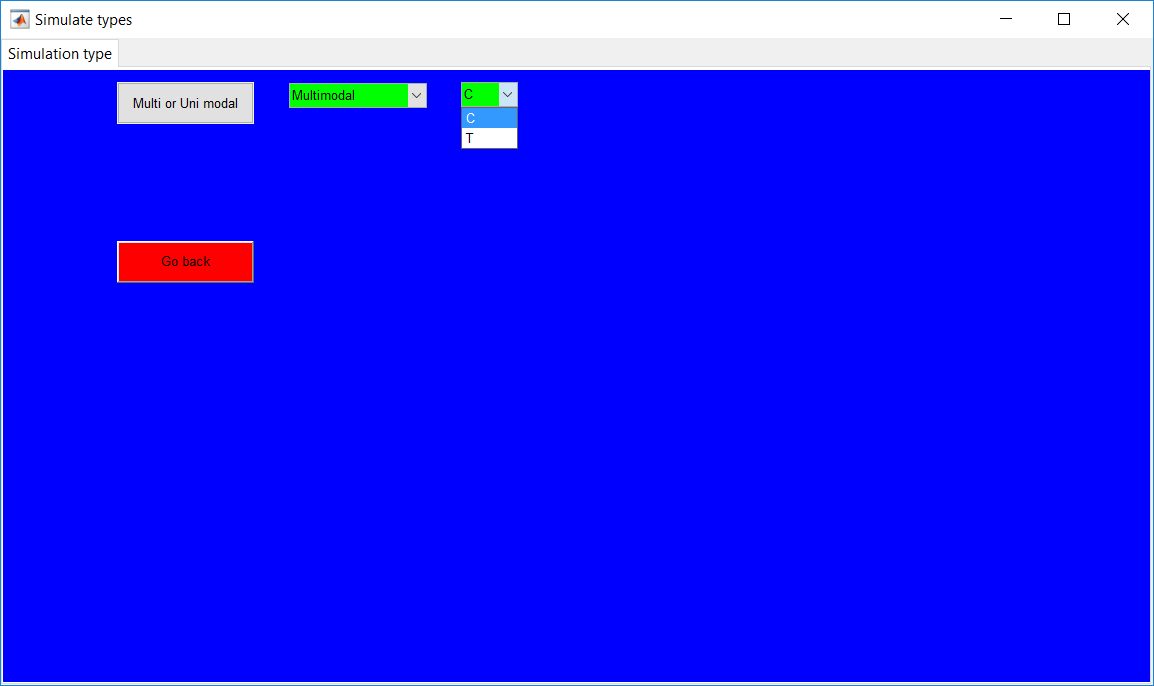
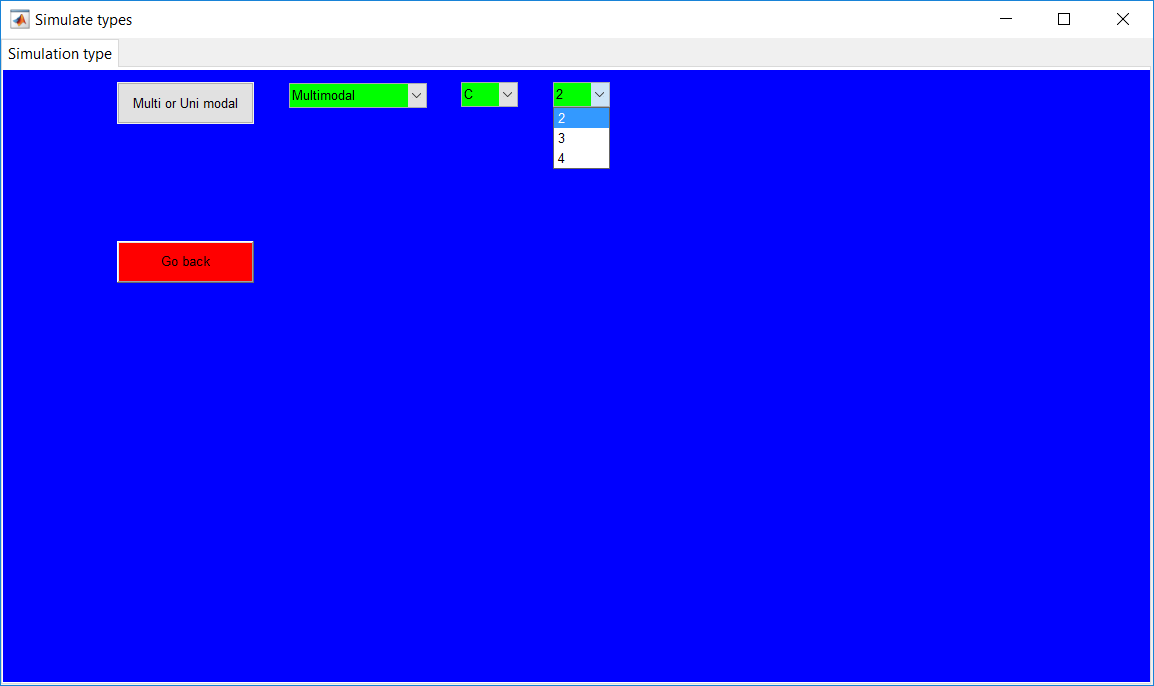
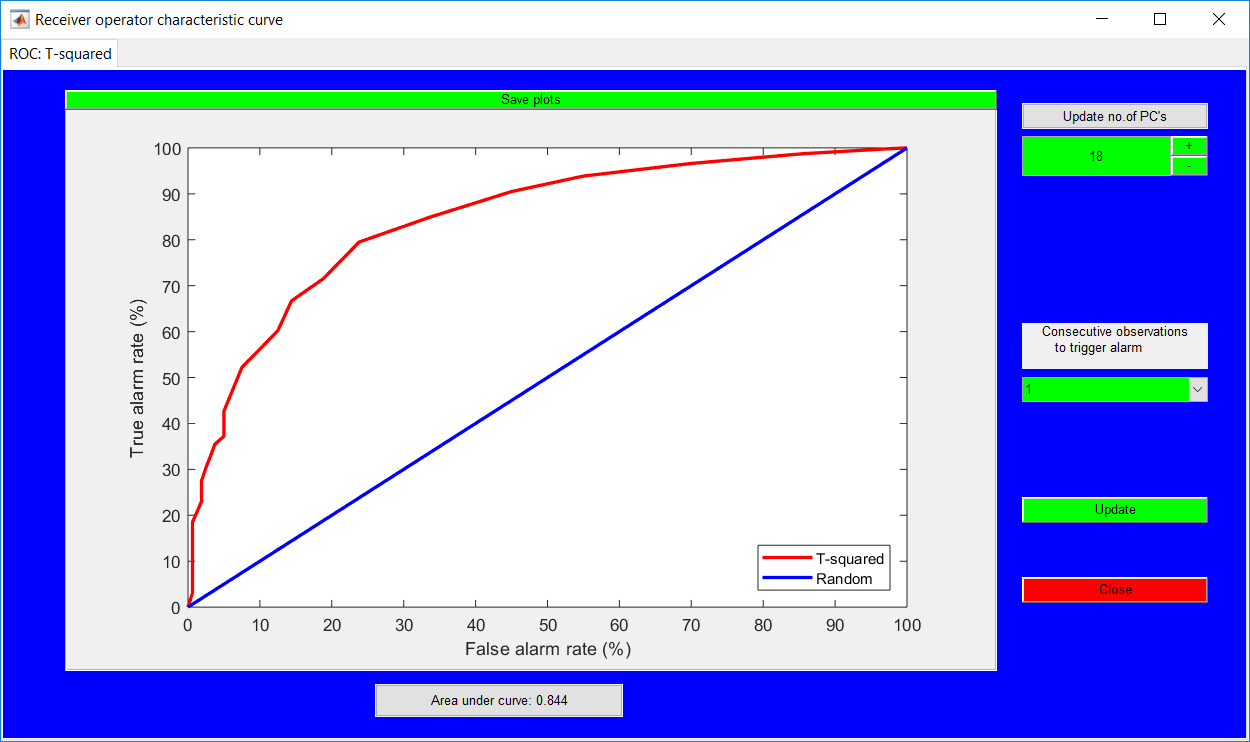
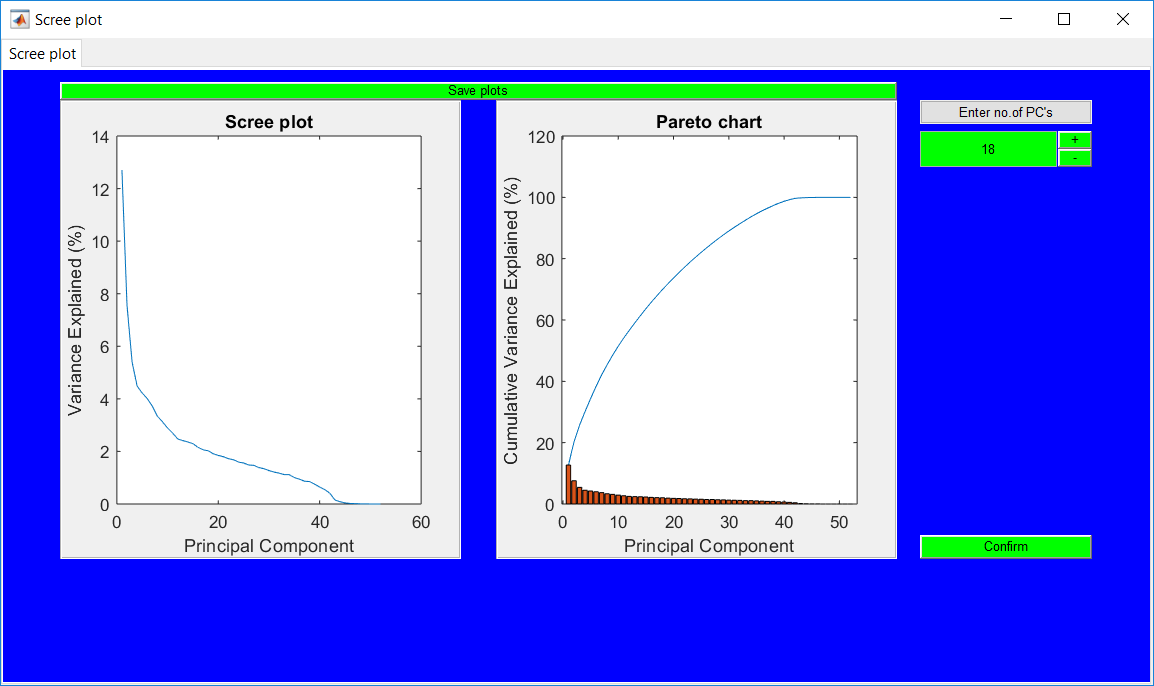
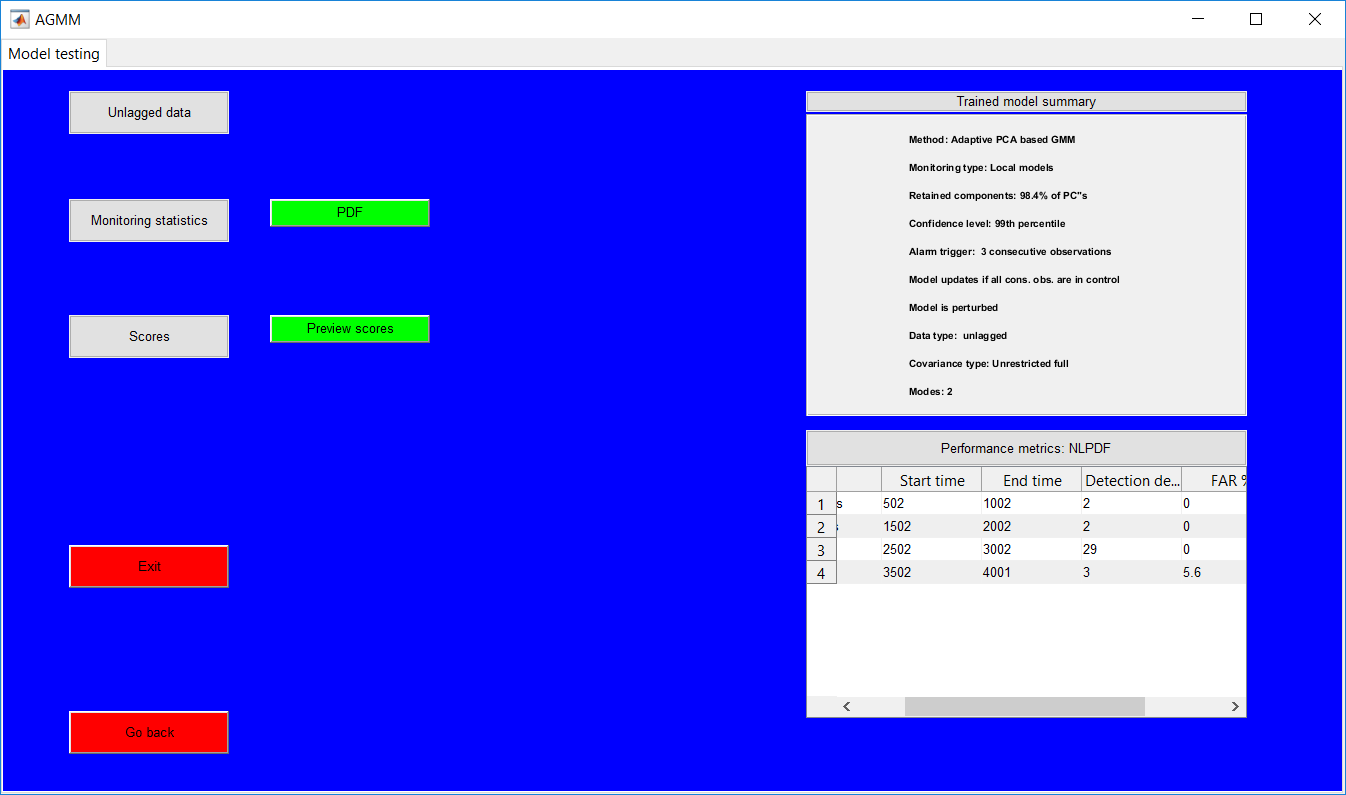
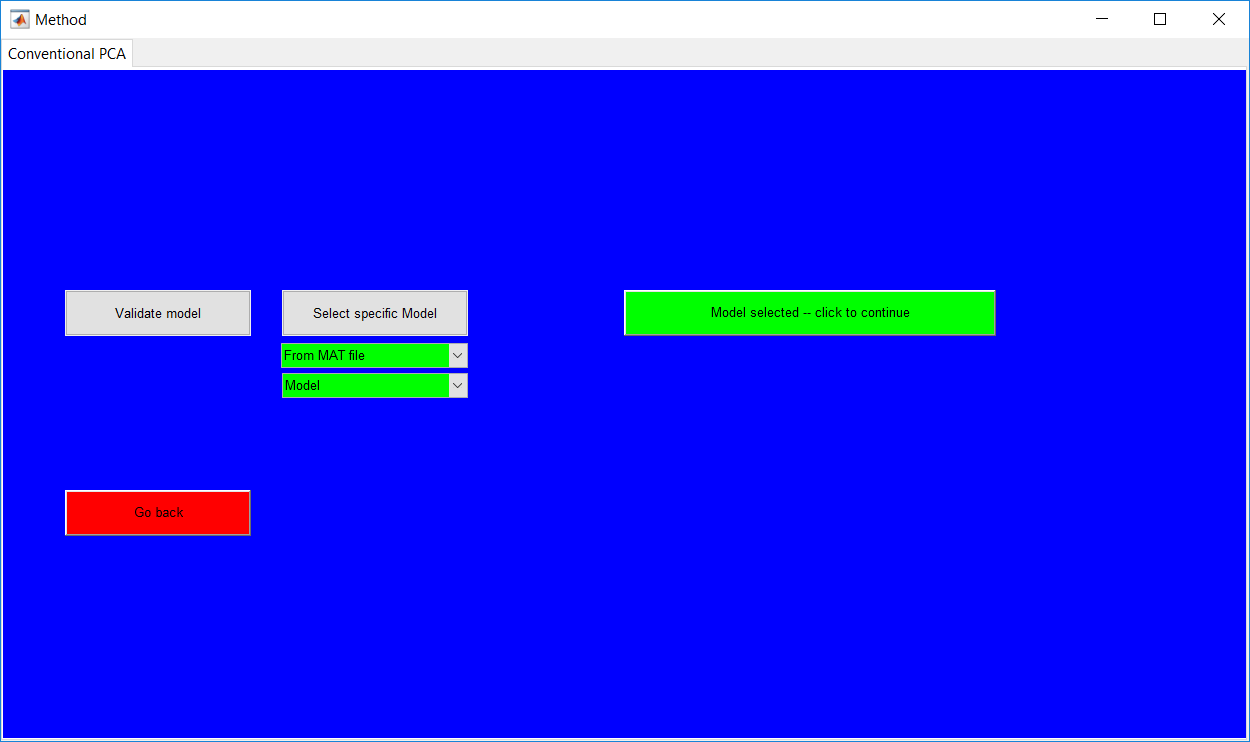
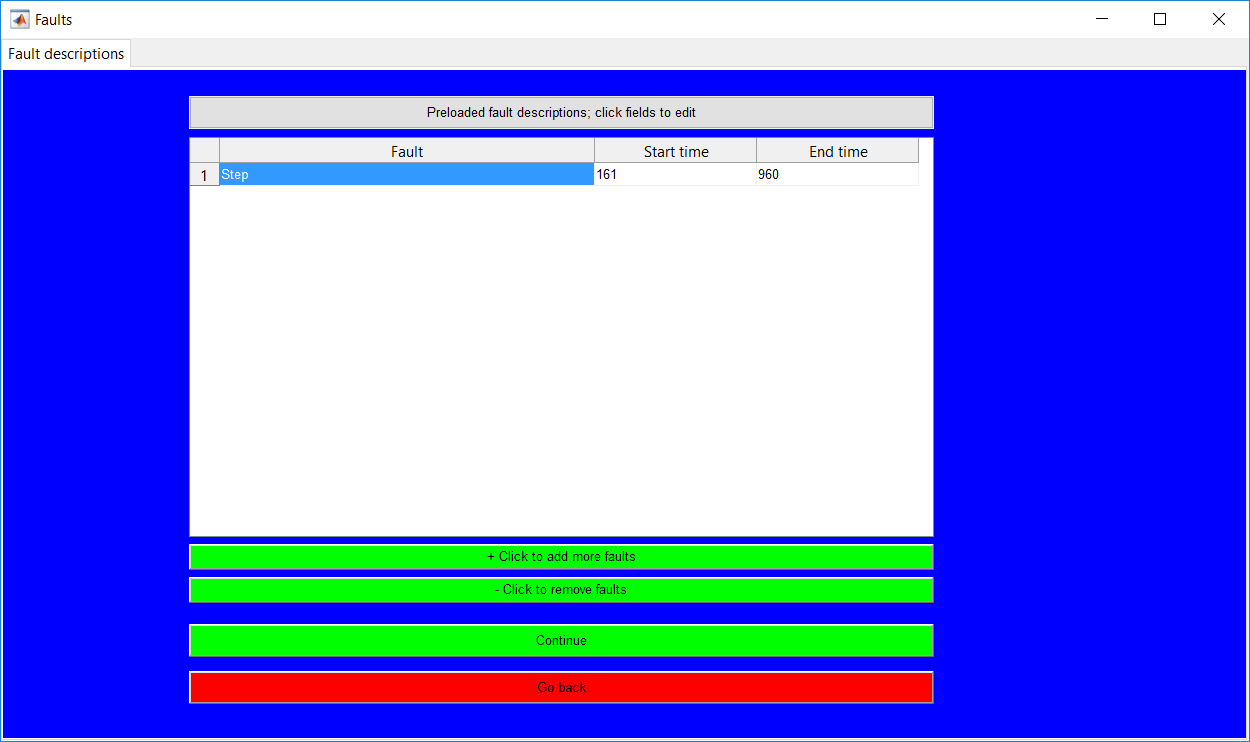
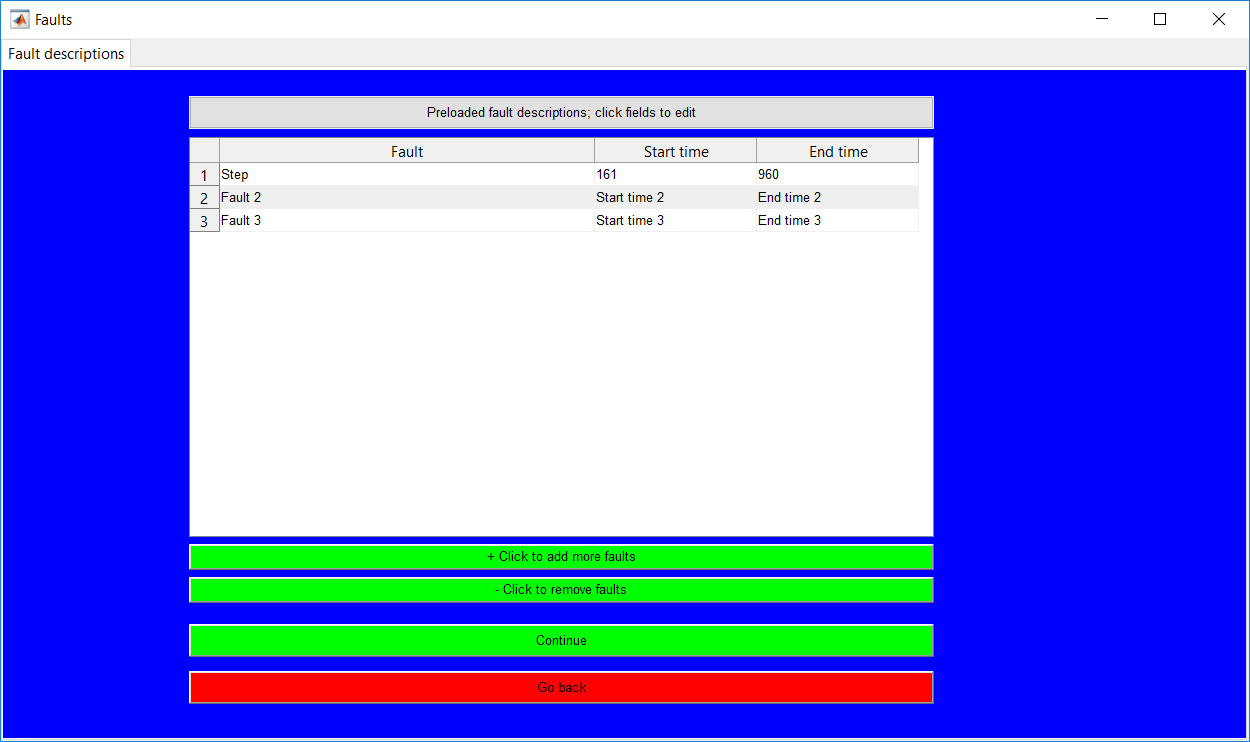
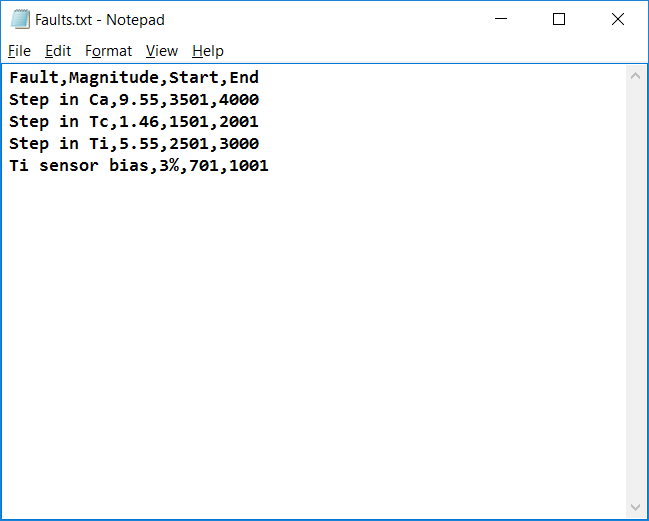
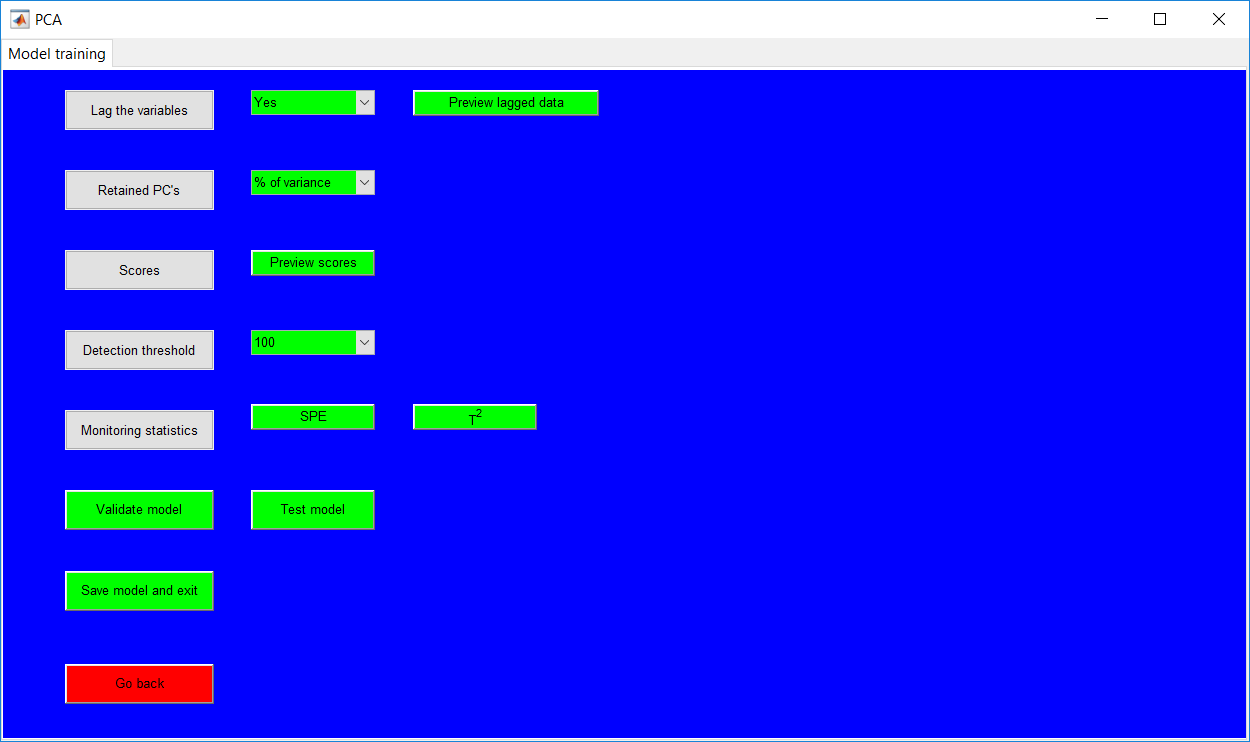
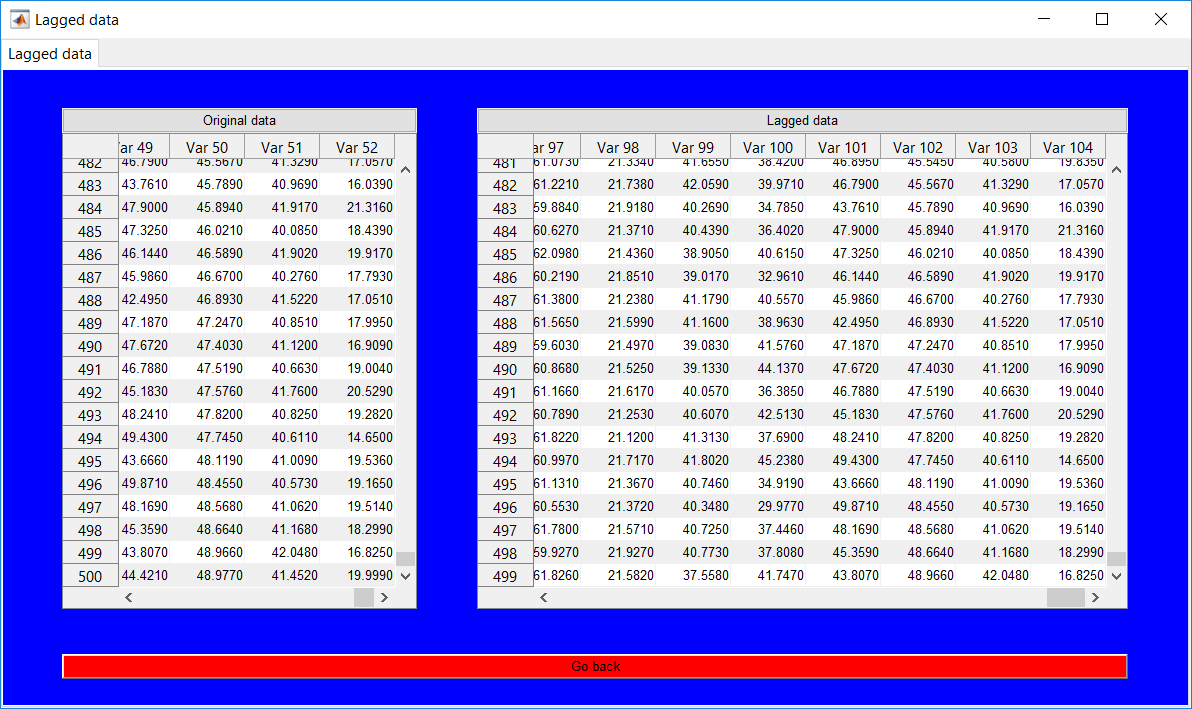
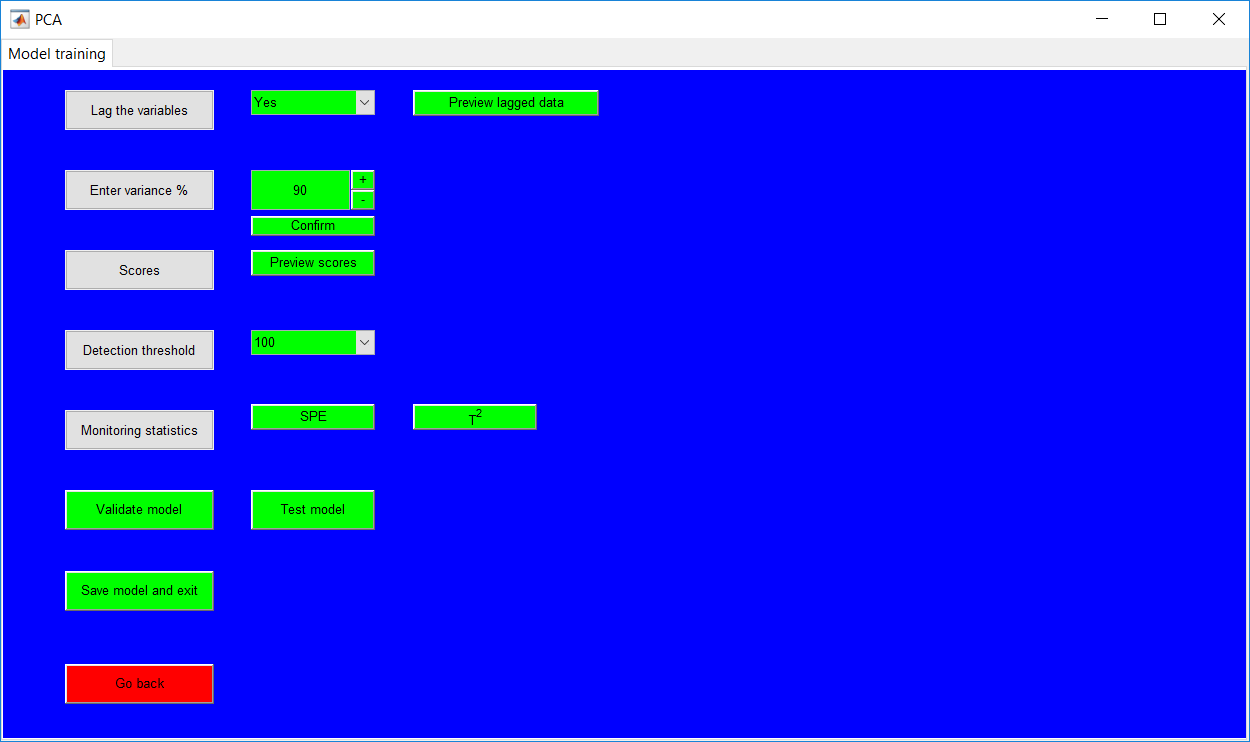
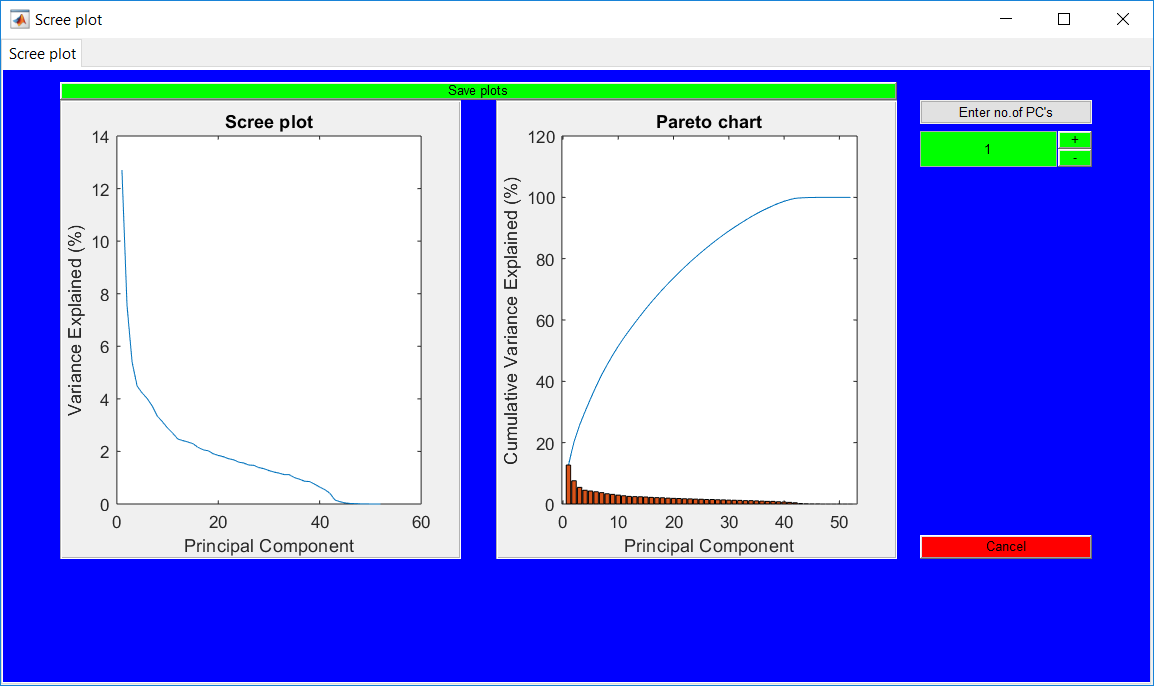
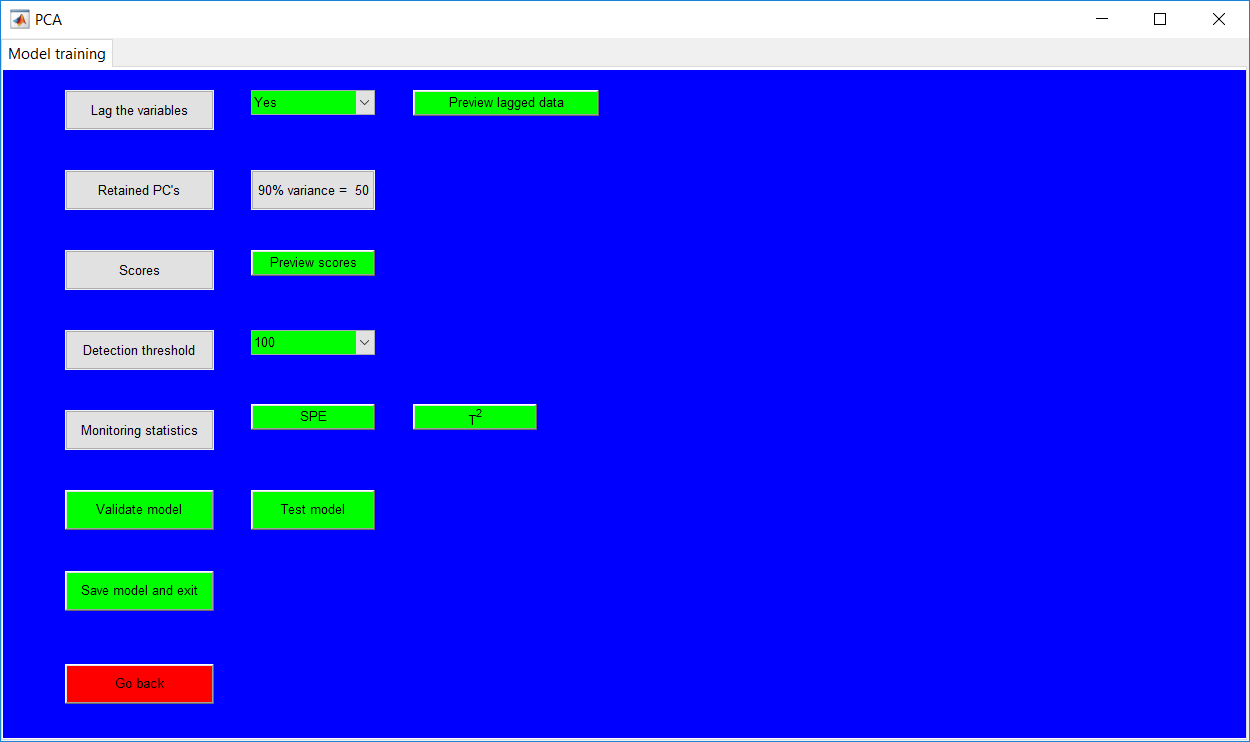
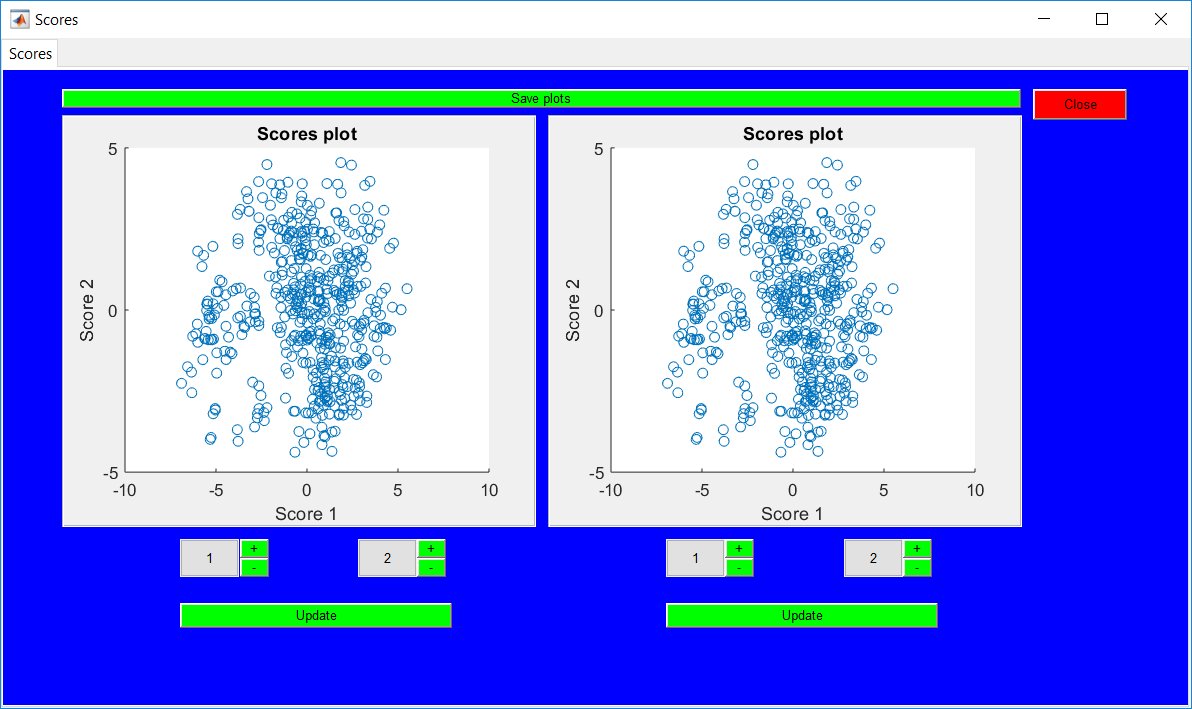
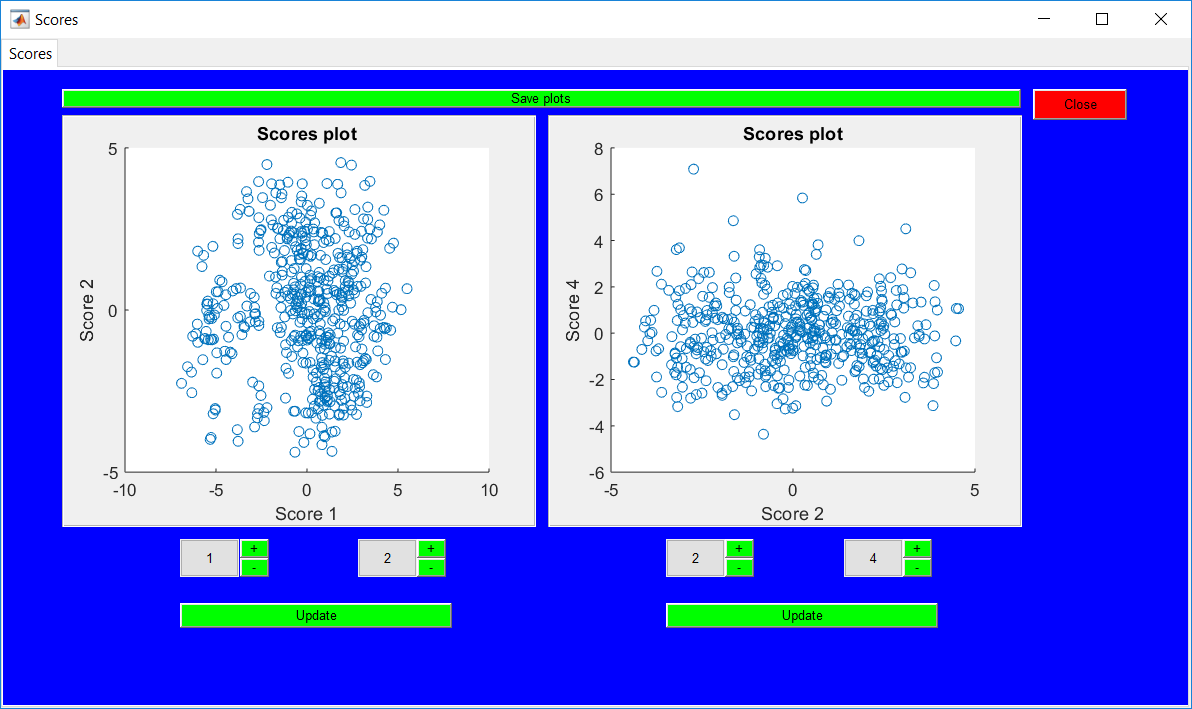
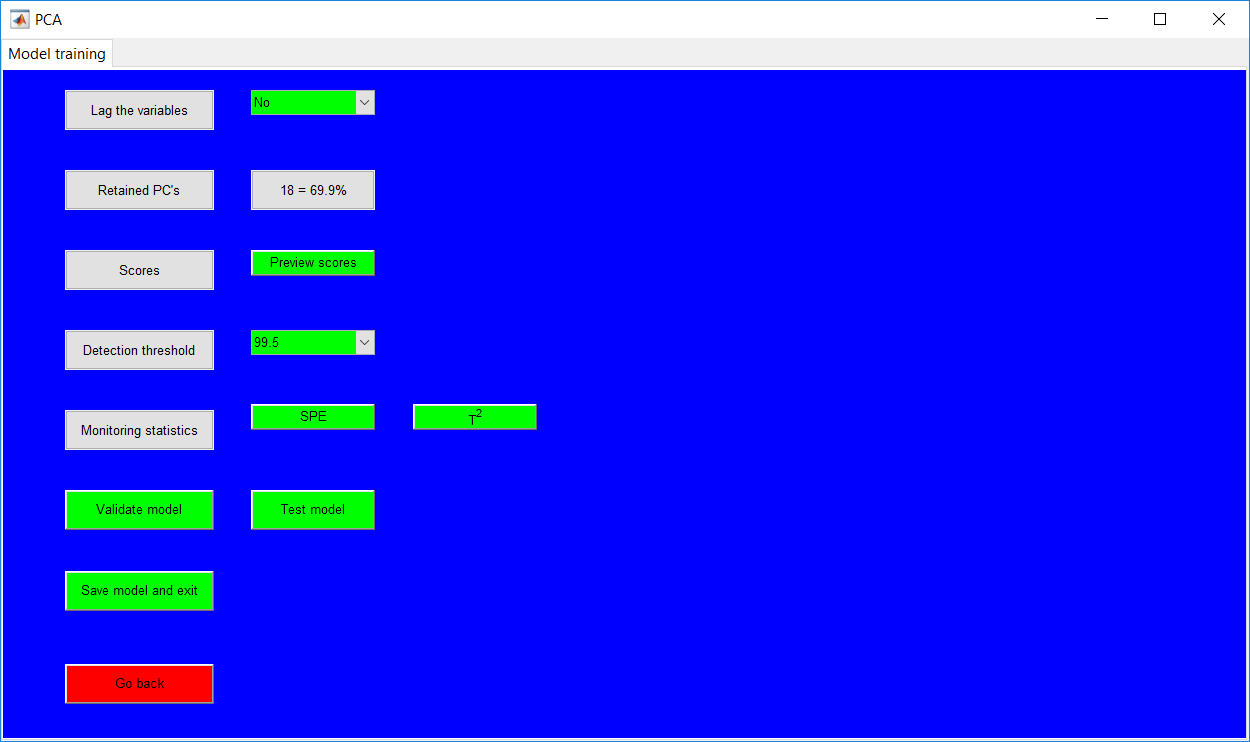
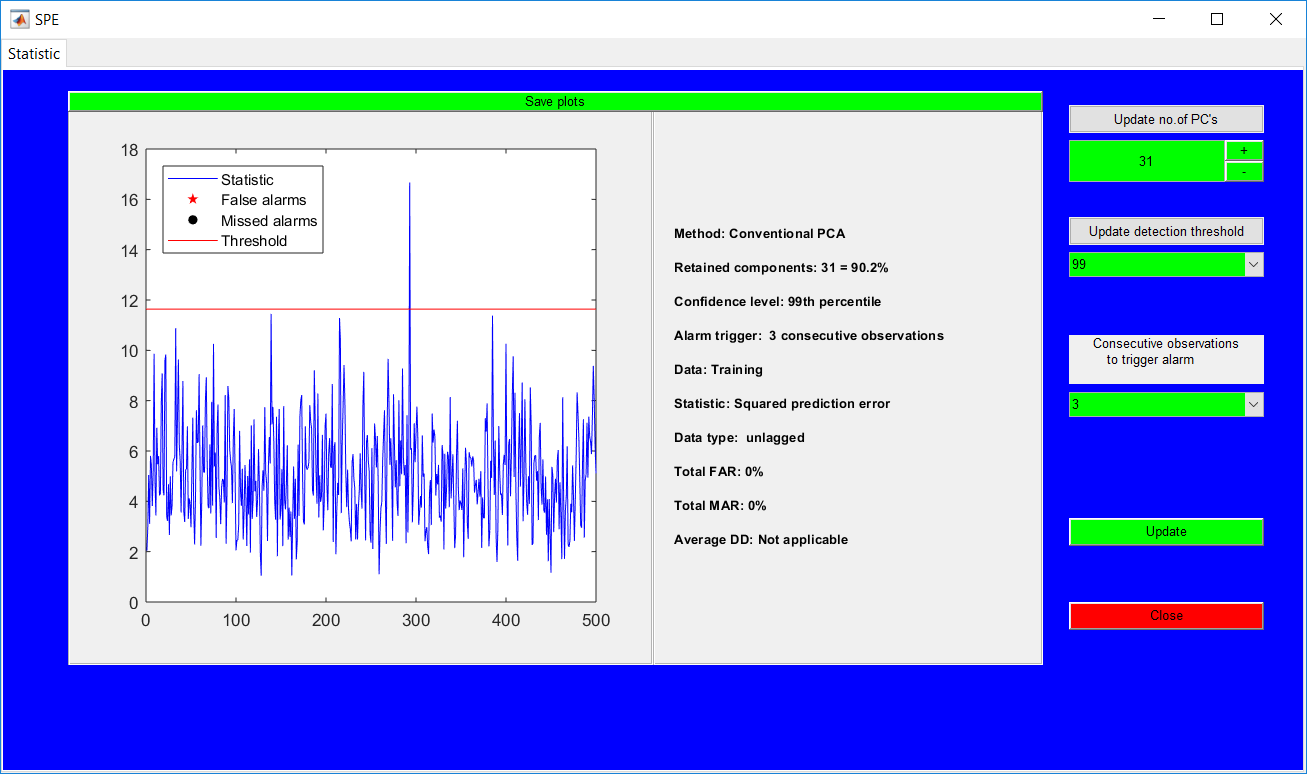
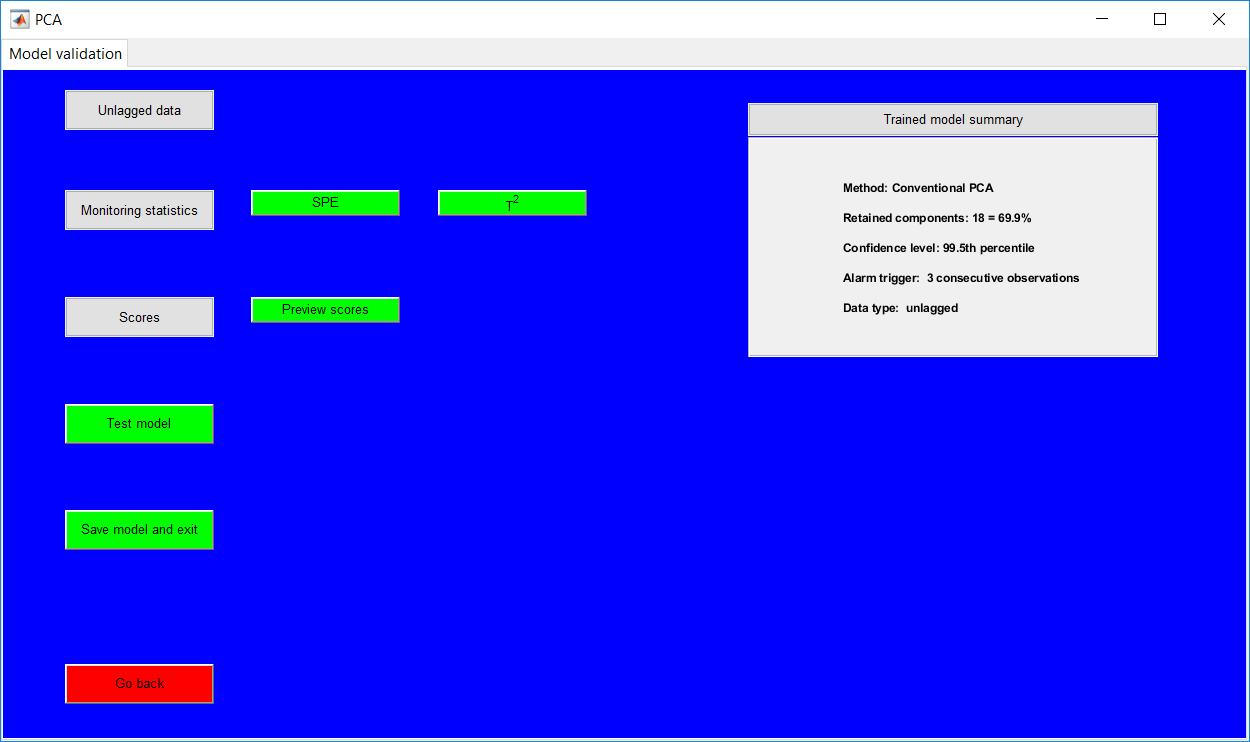
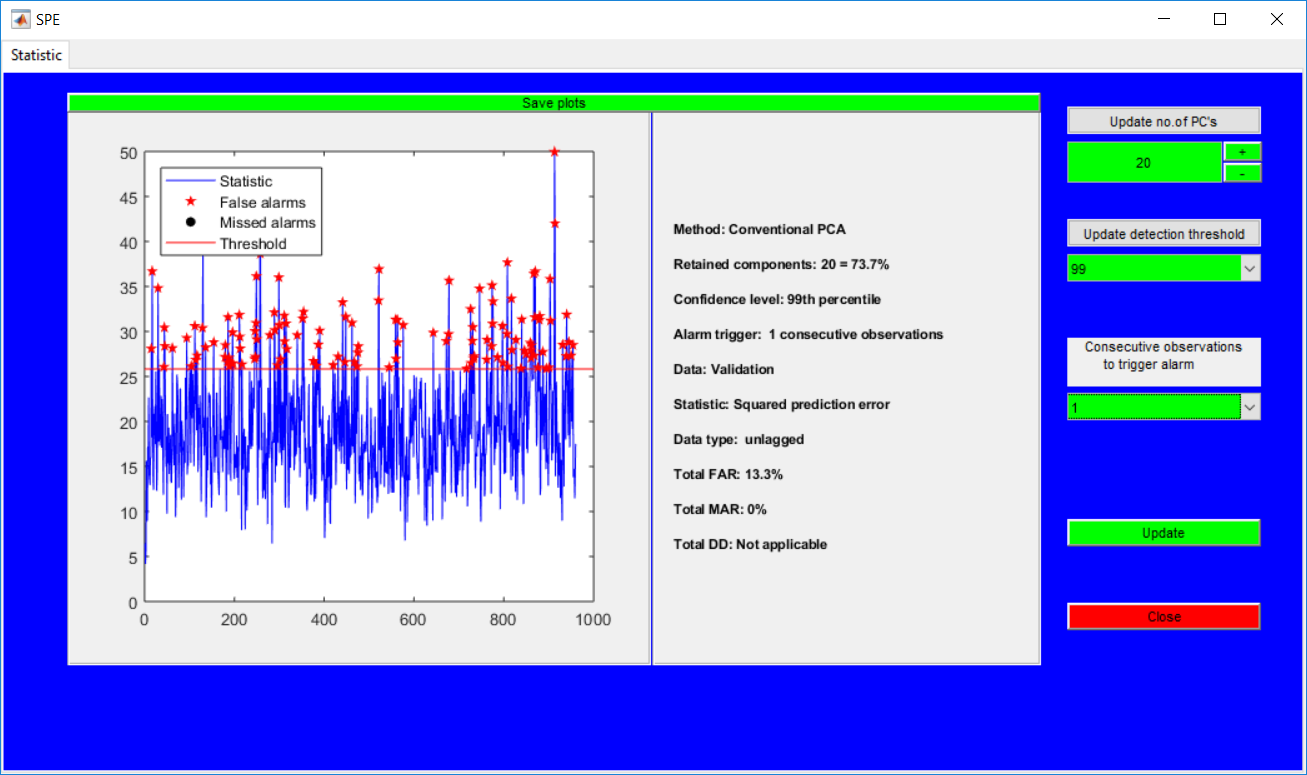
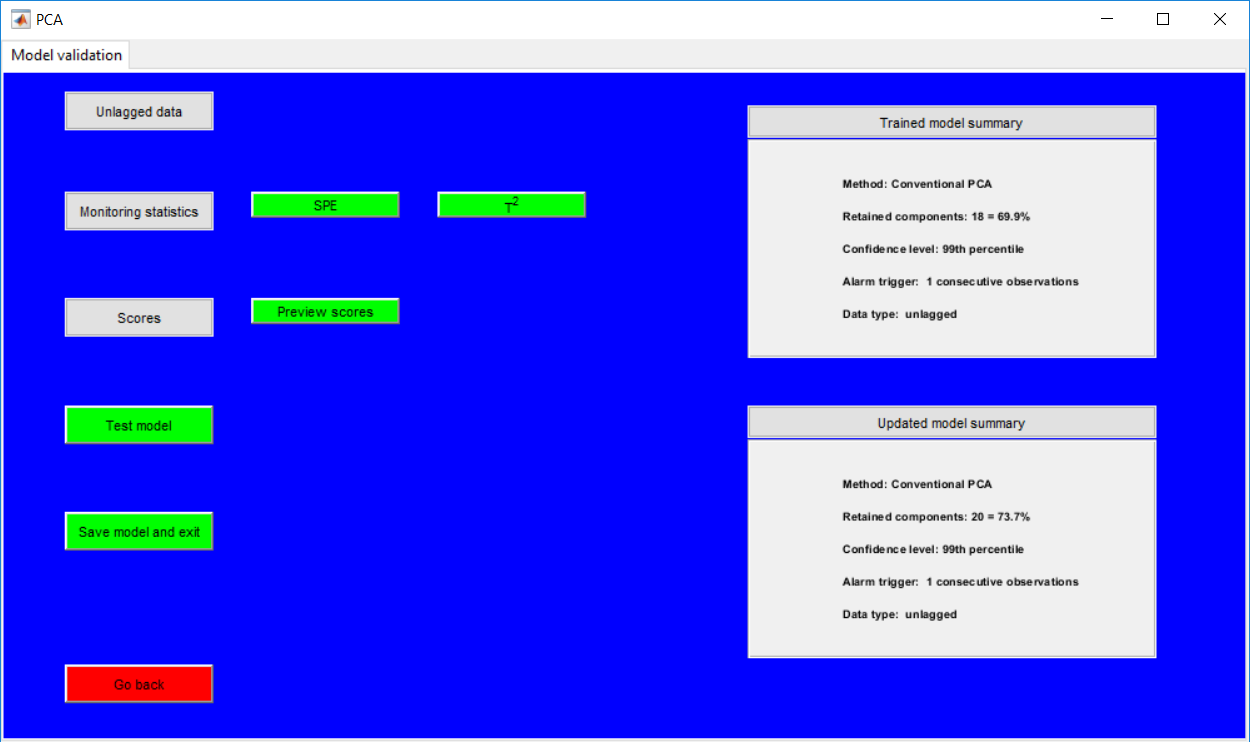
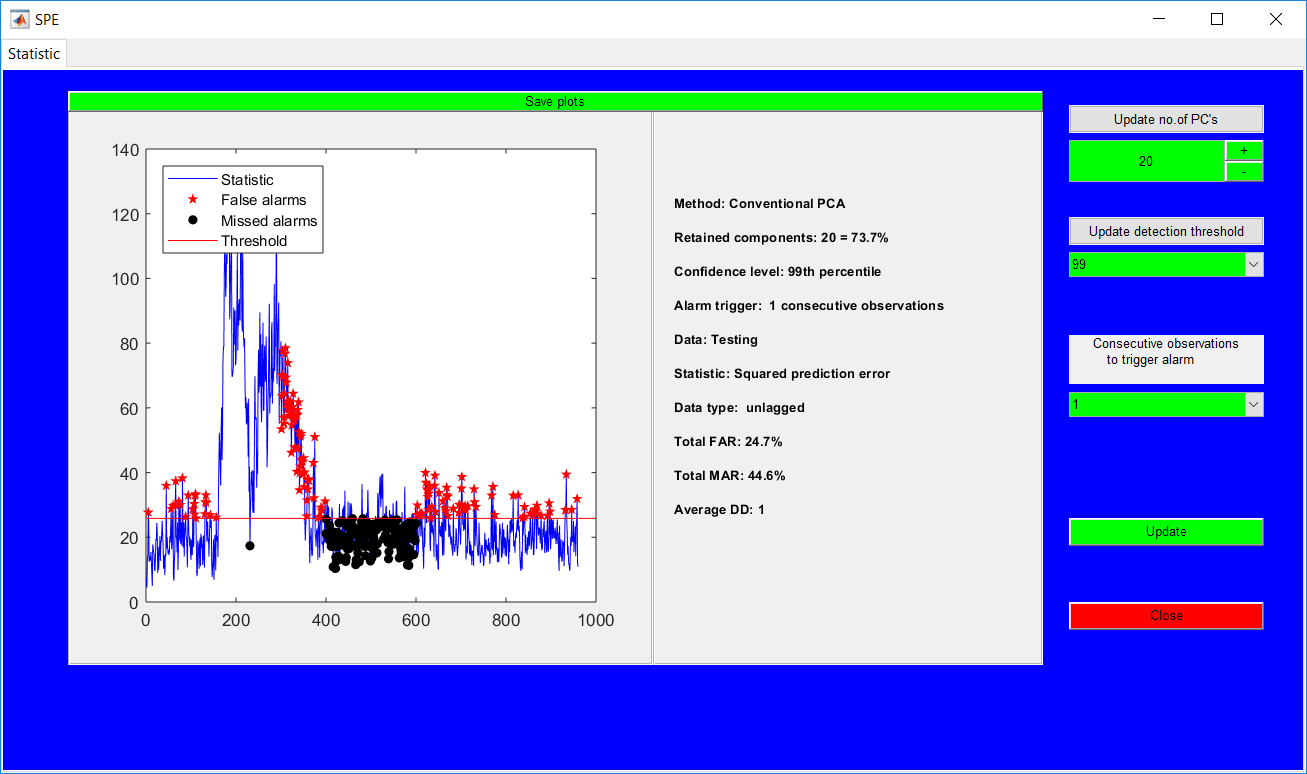
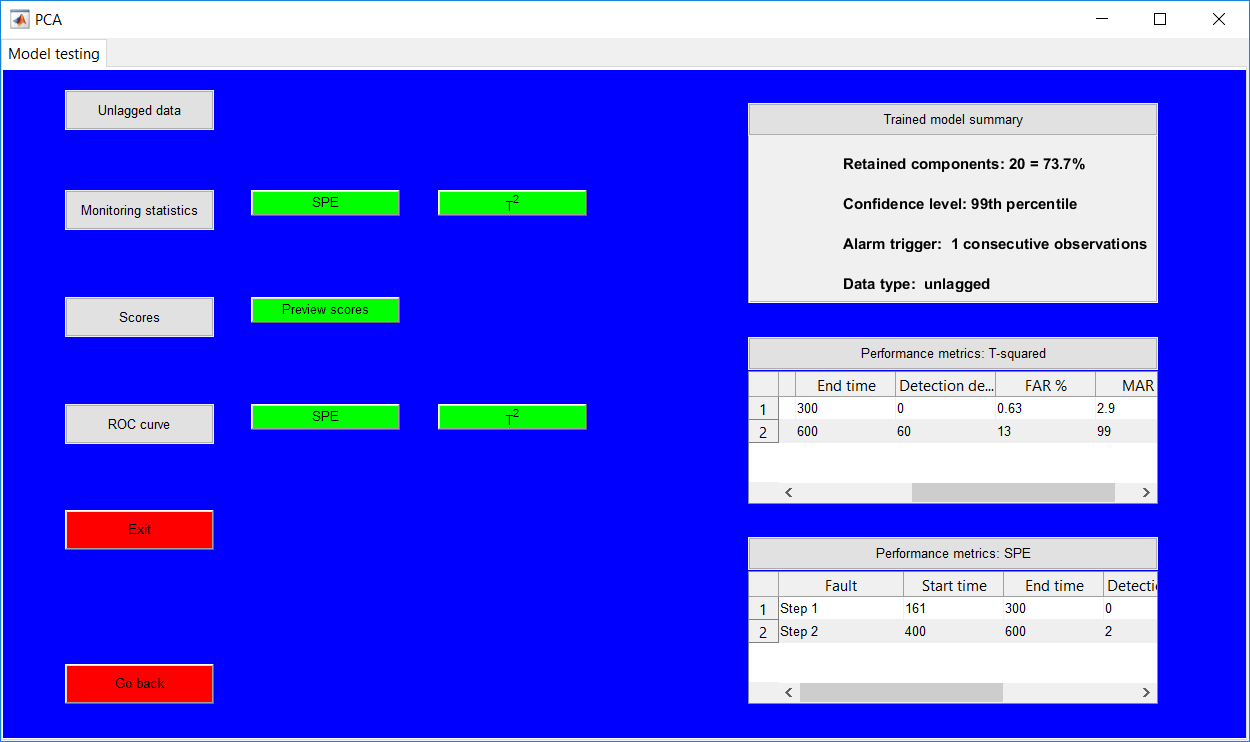
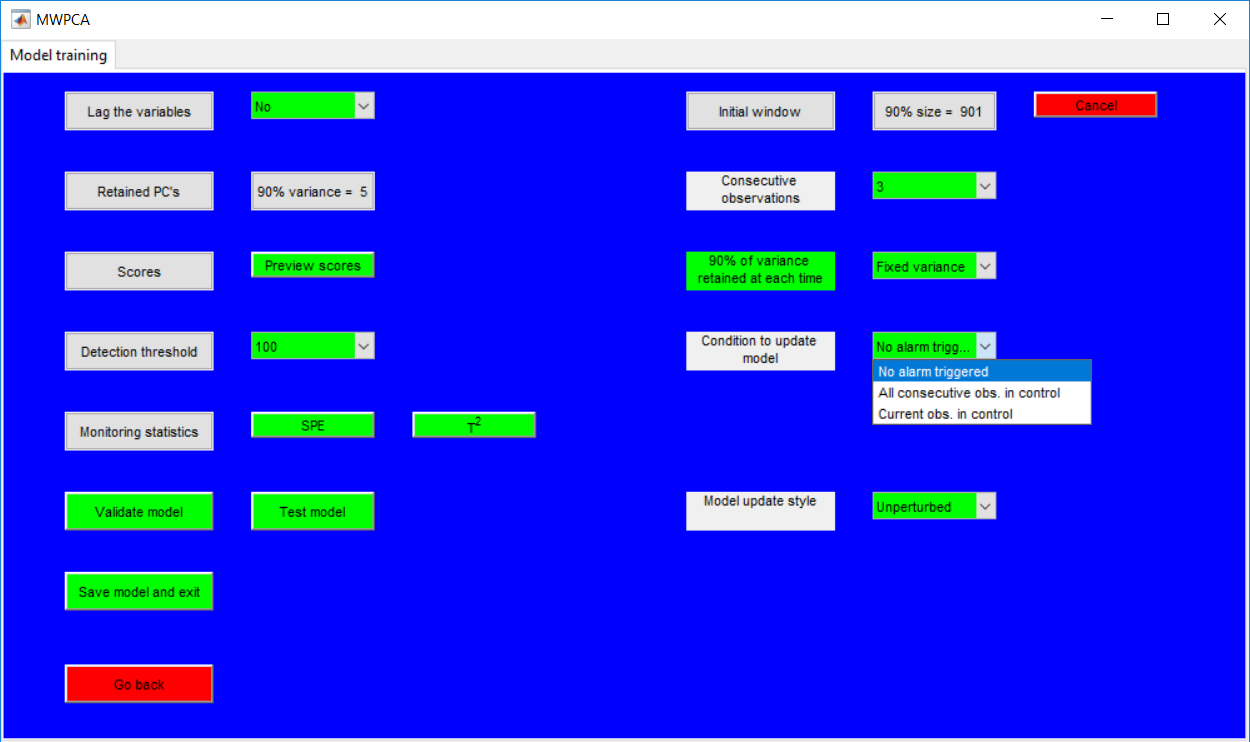
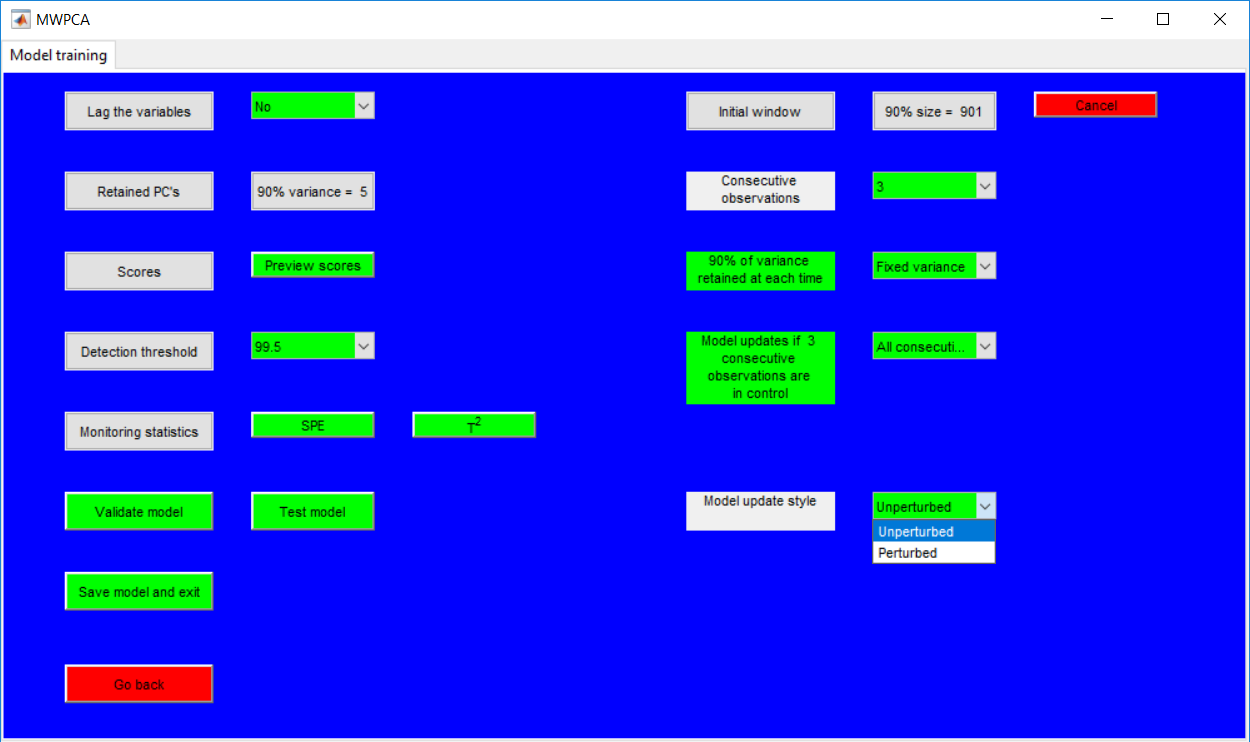
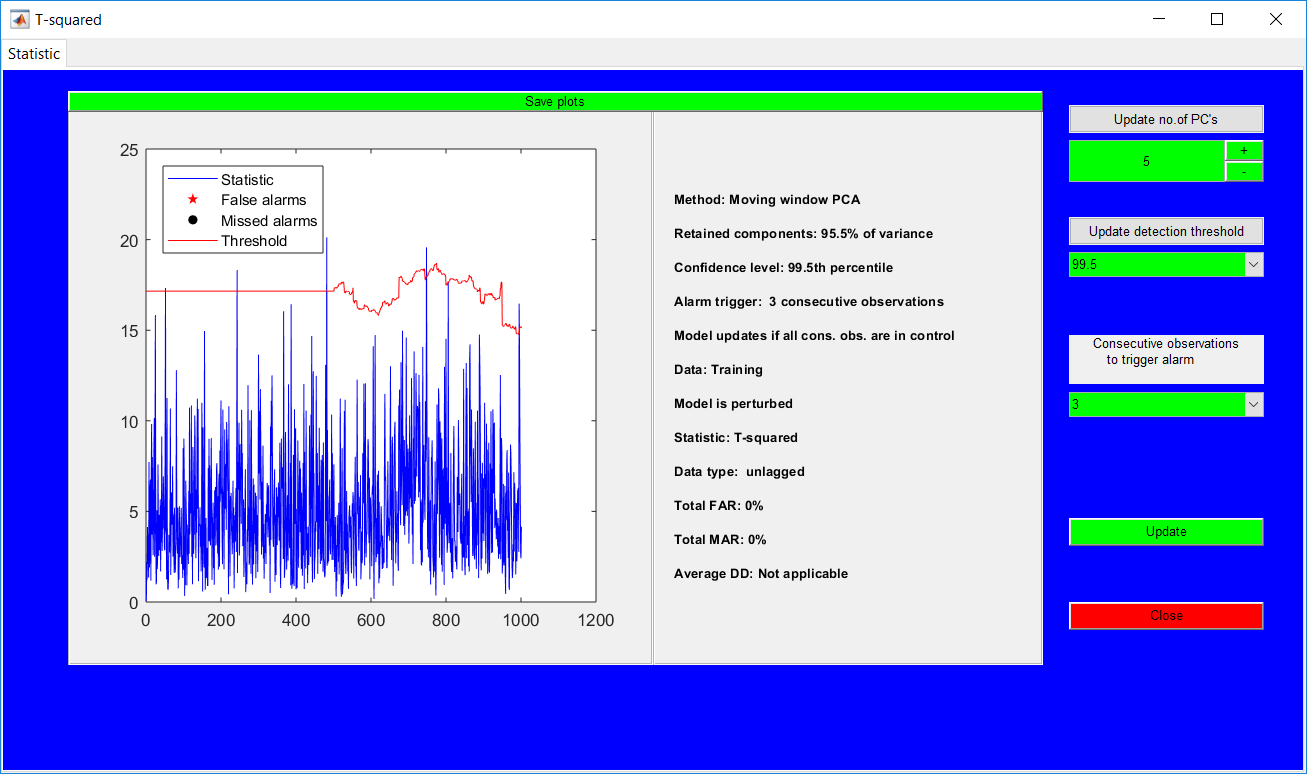
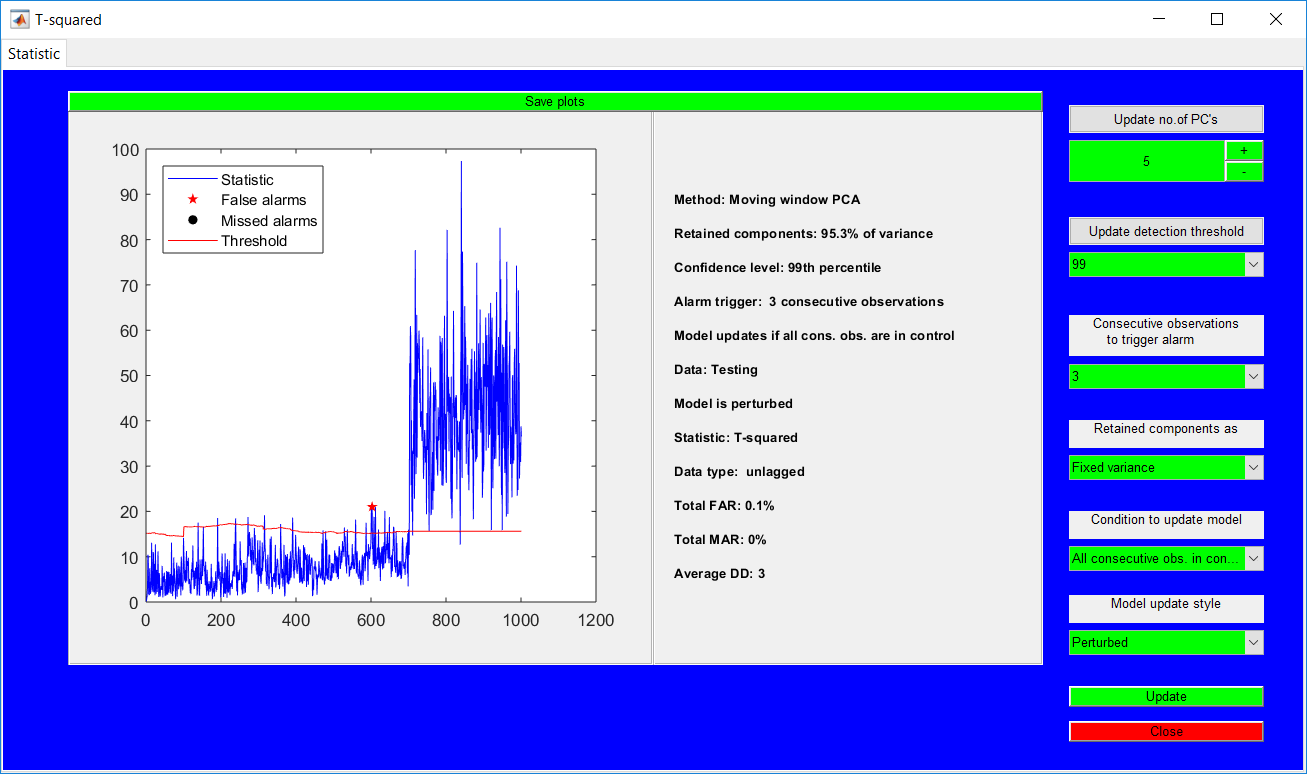
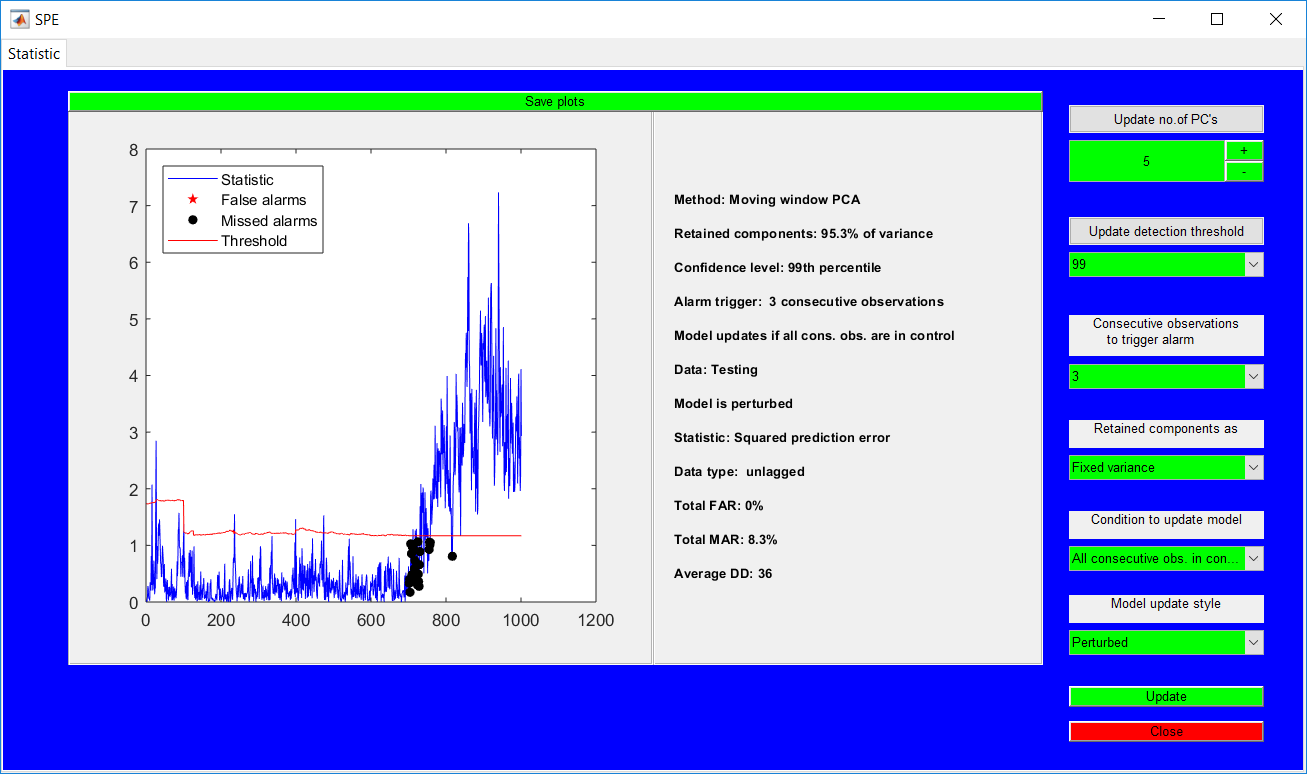
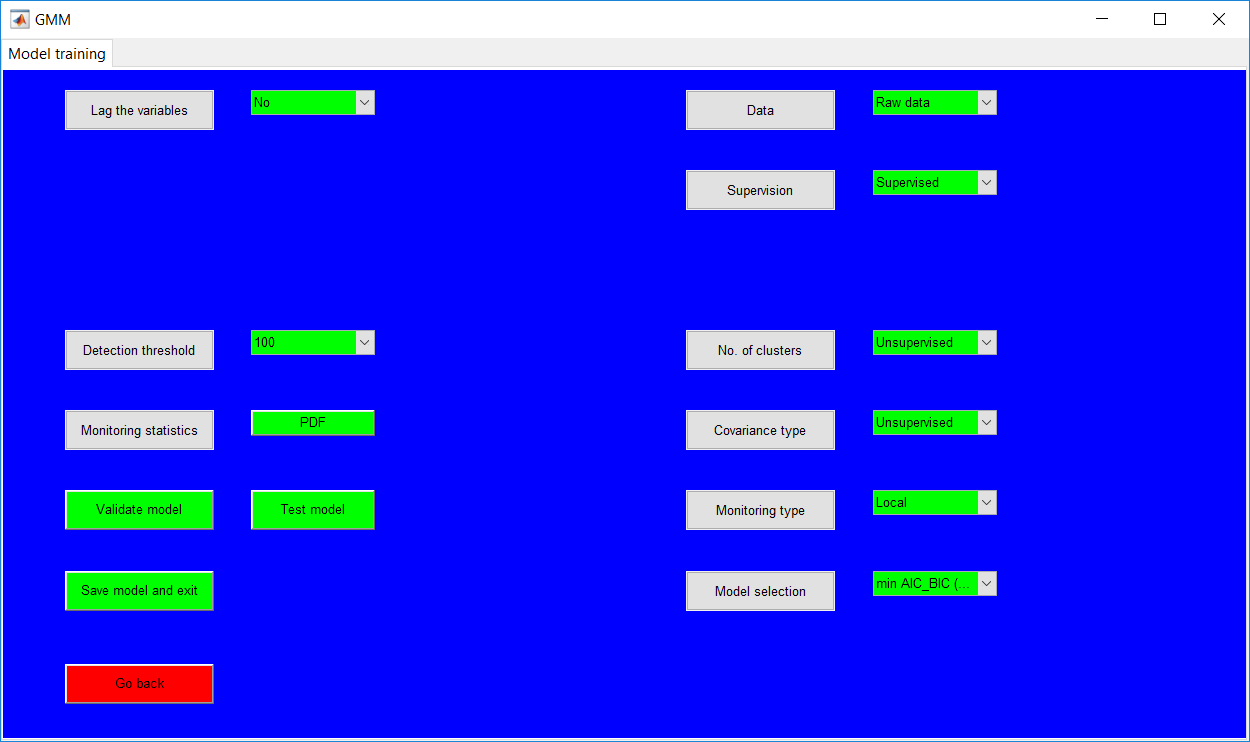
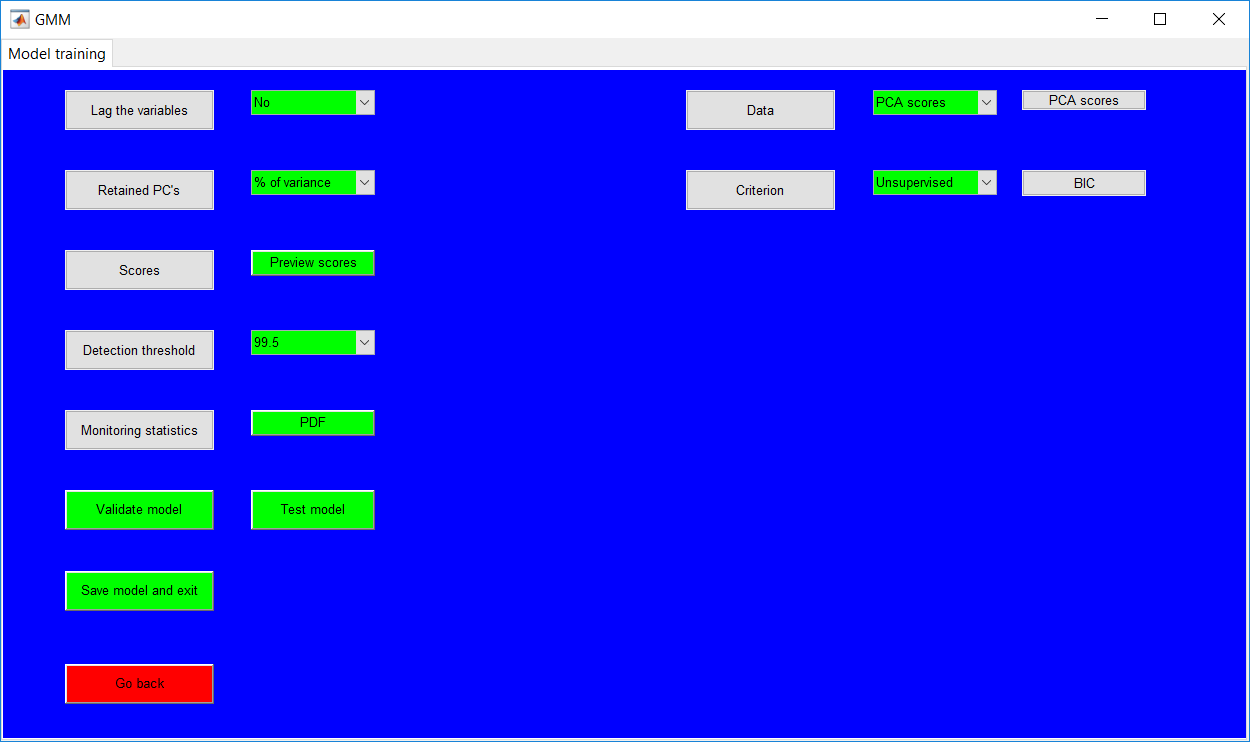
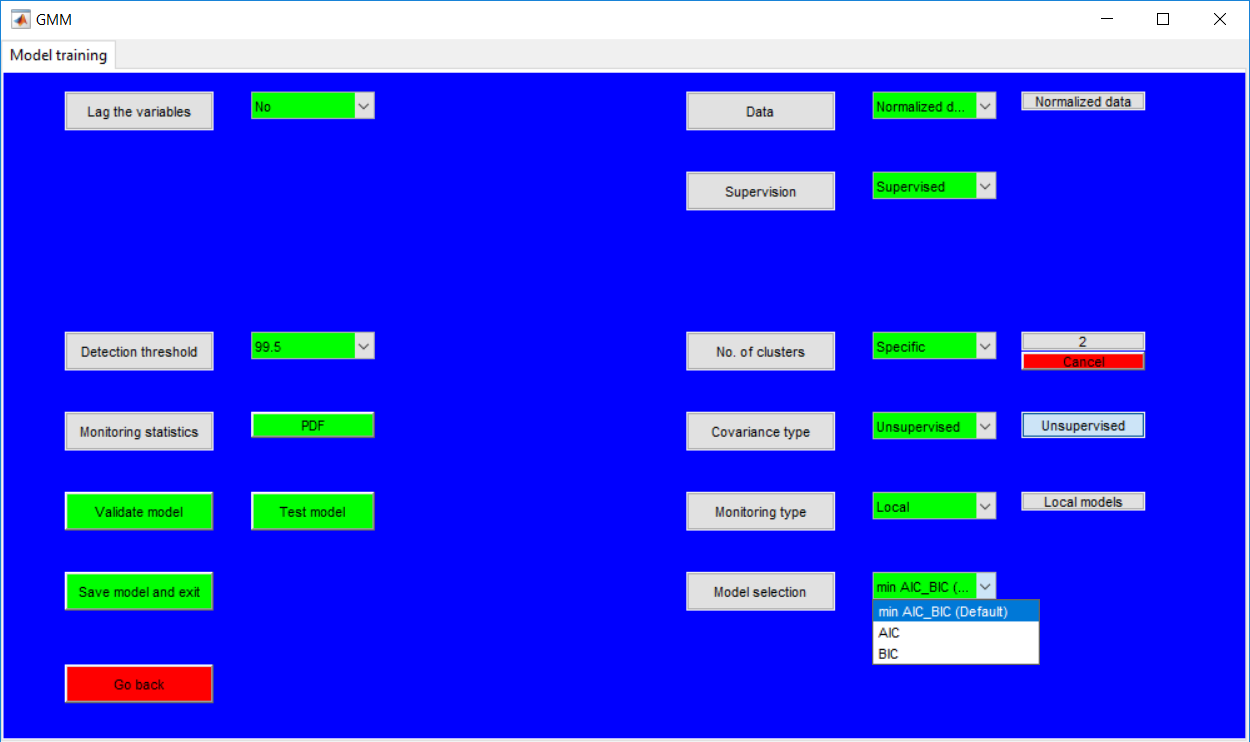
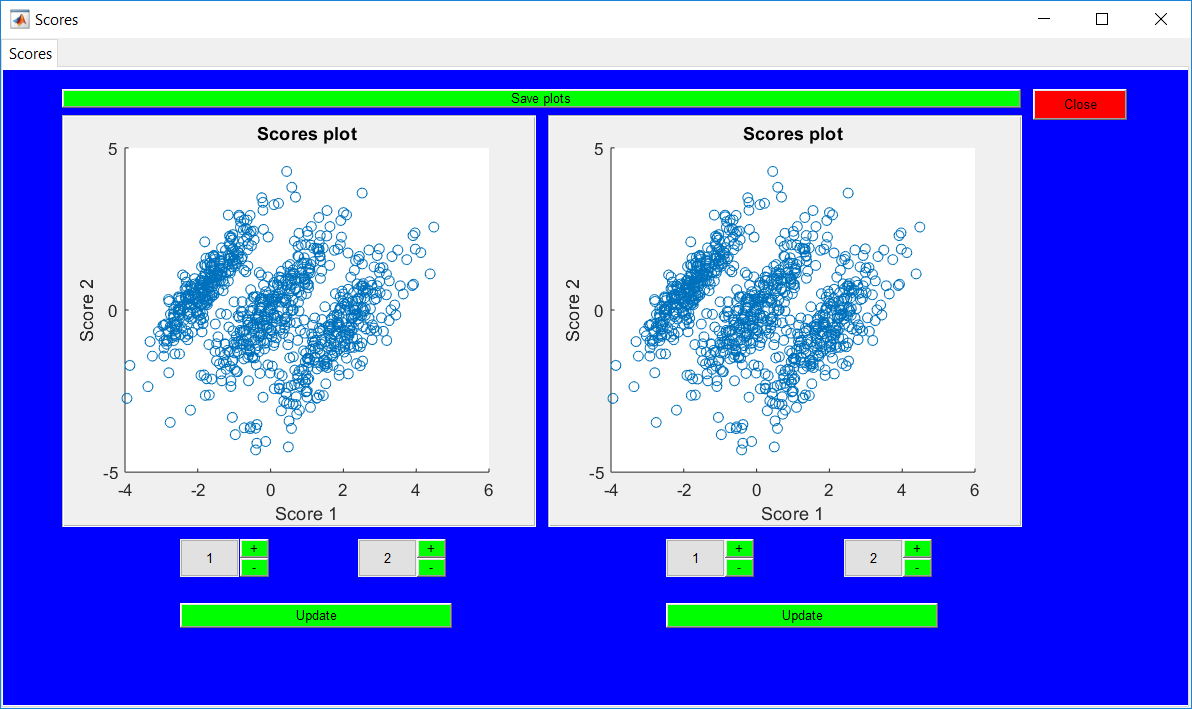
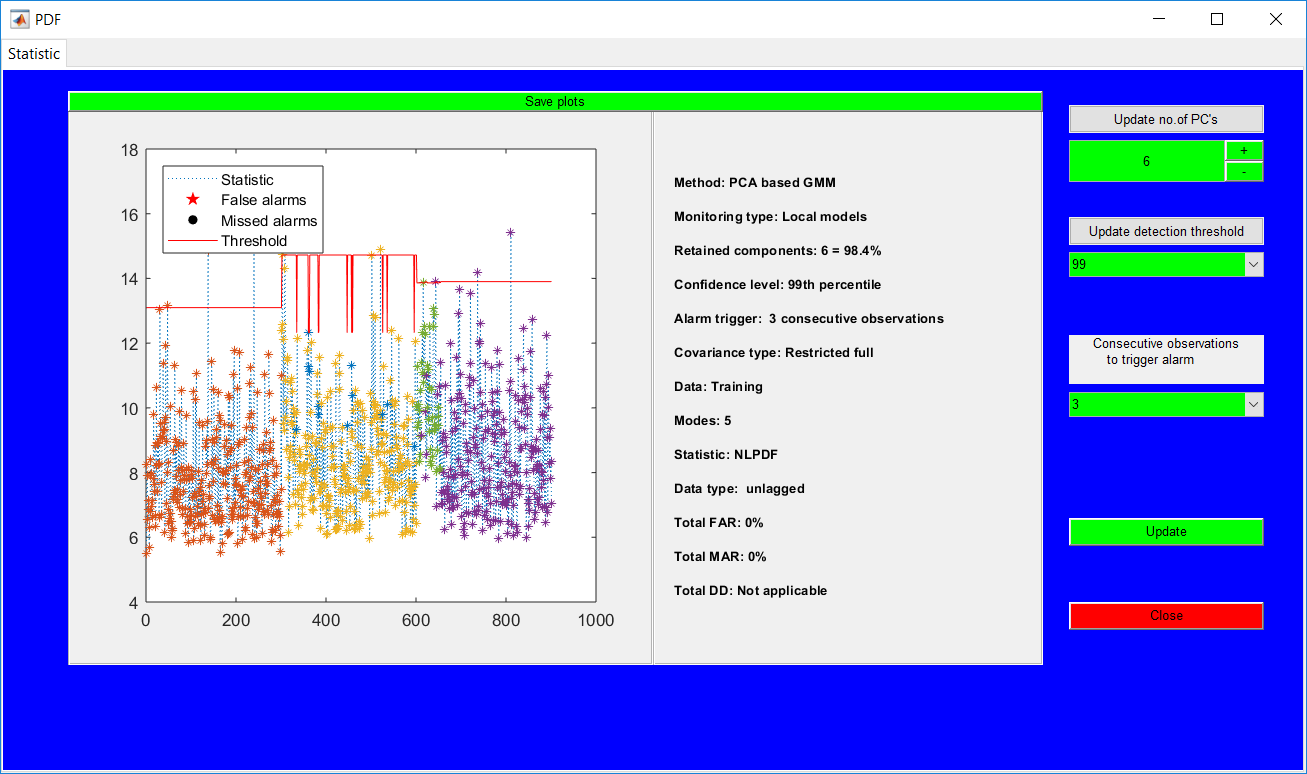
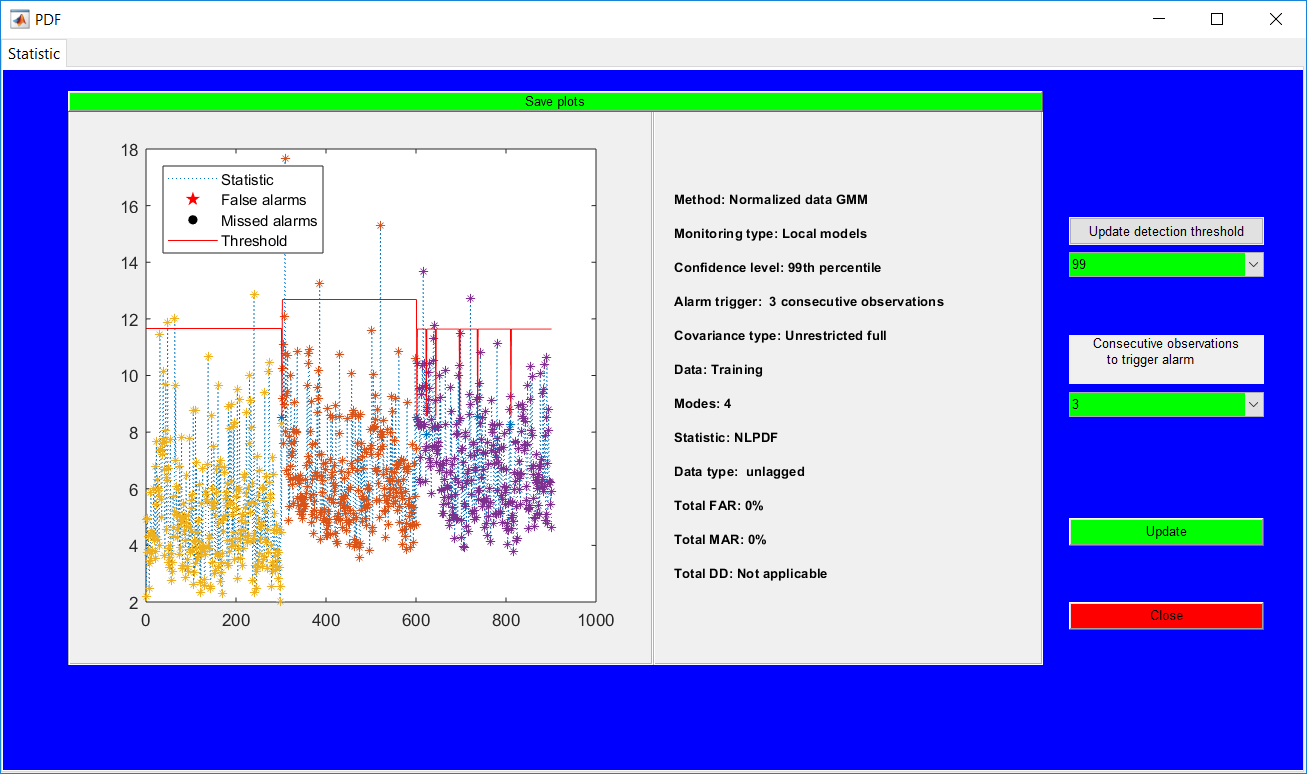
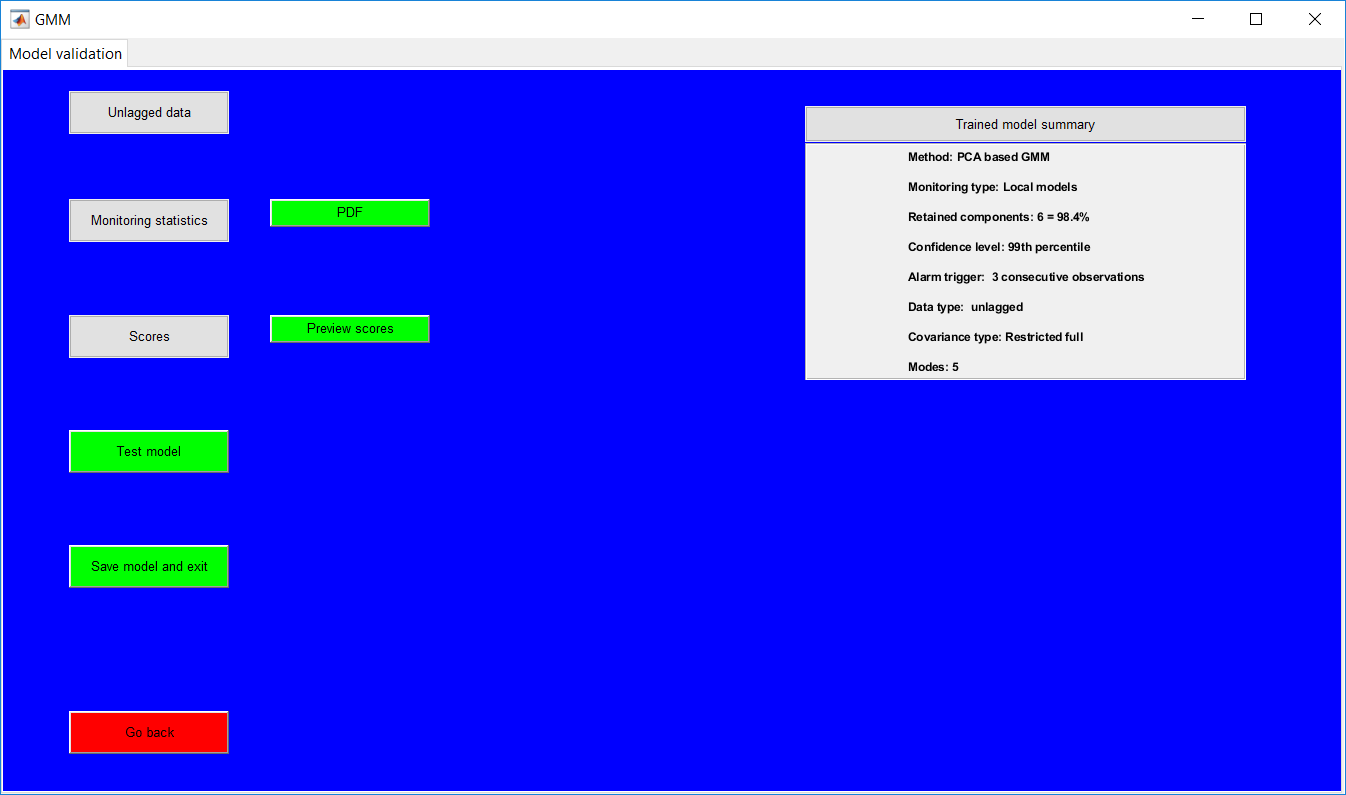
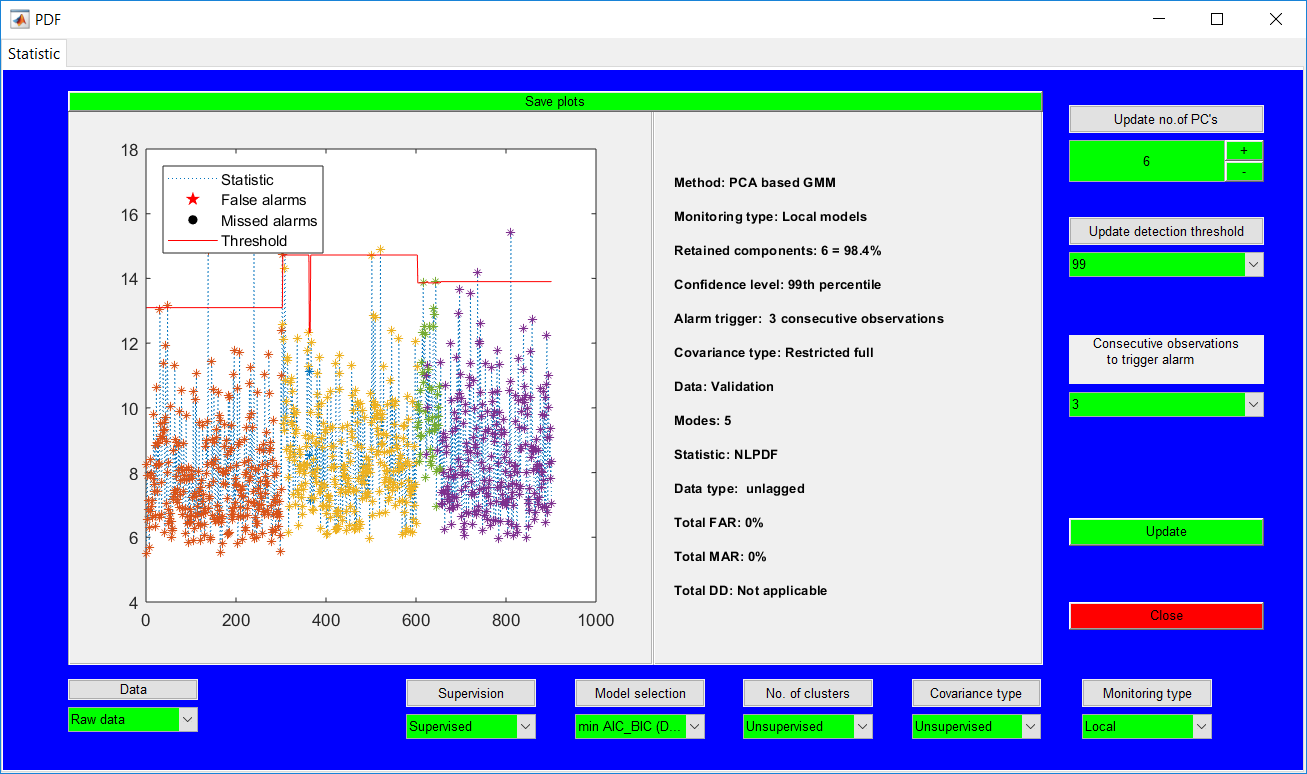
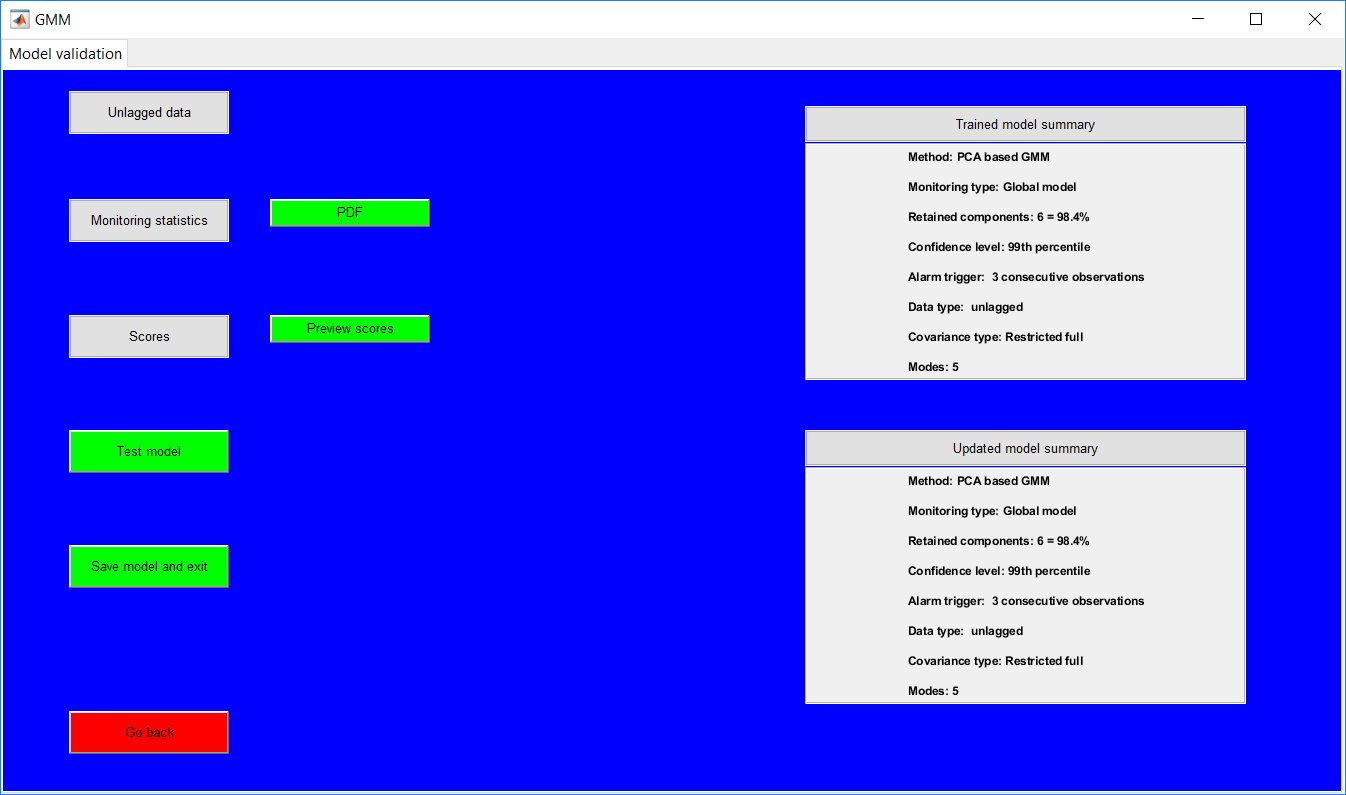
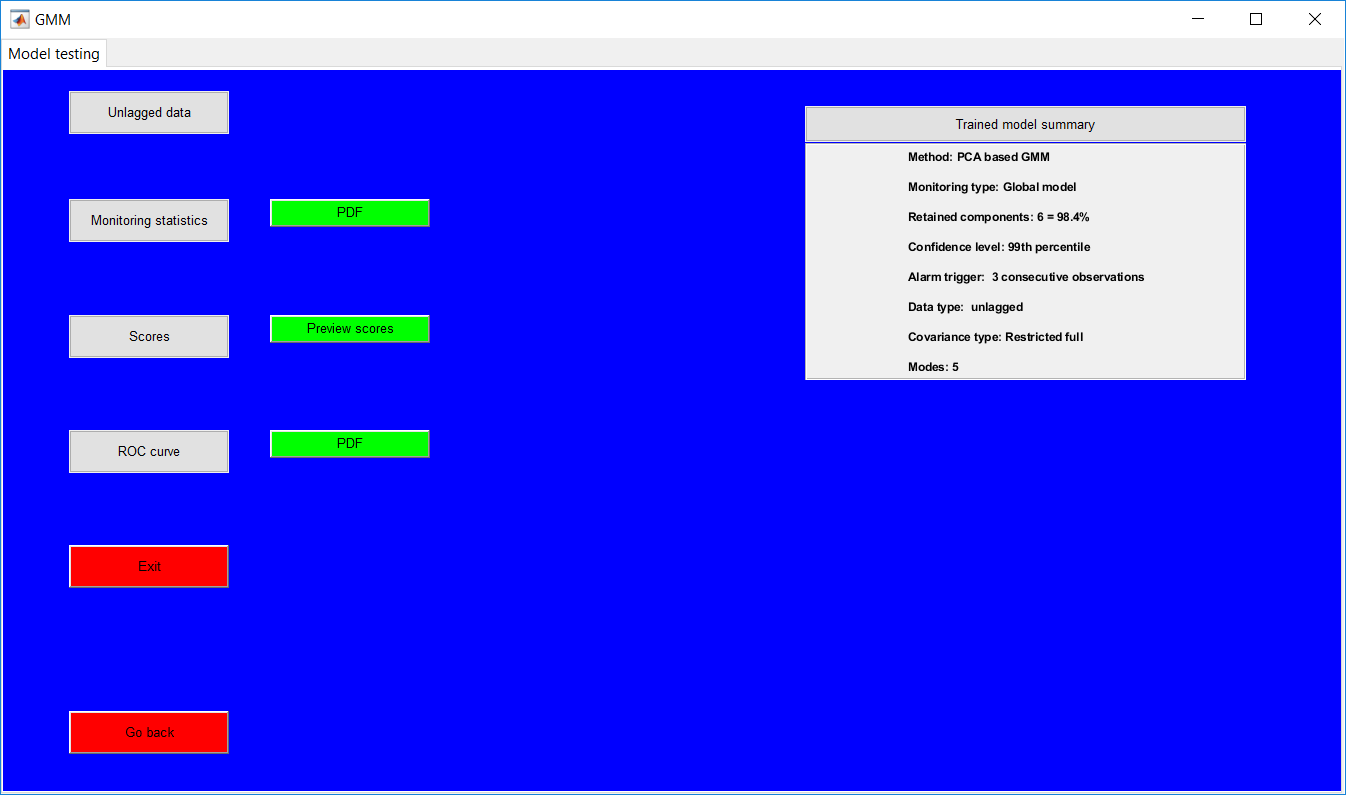
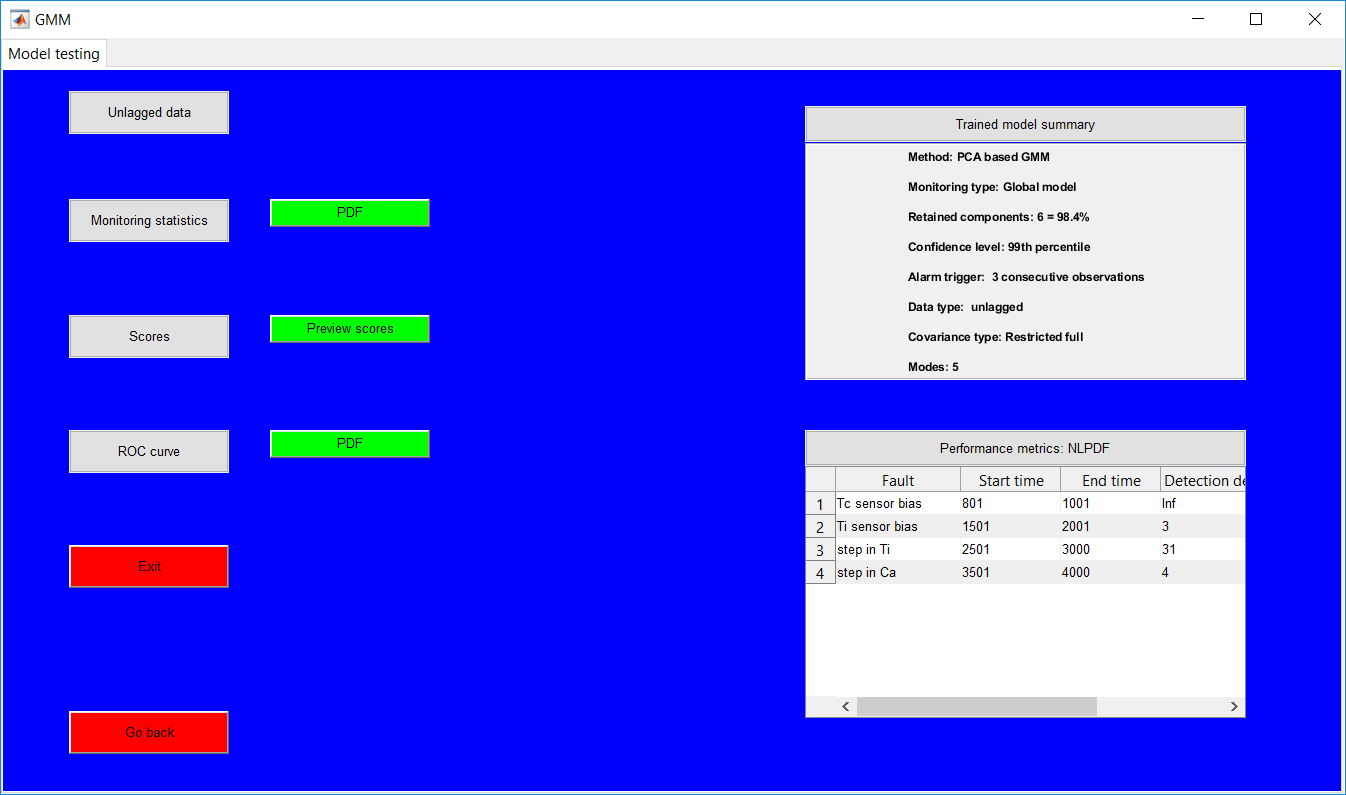
This work builds a toolbox that employs principal component analysis (PCA), adaptive PCA (APCA) as well as Gaussian mixture models (GMM) and adaptive GMM techniques. Moving window PCA (MWPCA) and recursive PCA (RePCA) are the APCA techniques available. The toolbox supports model training, validation, and testing for various data types and faults. The unique approaches available are PCA, MWPCA, RePCA, GMM, and adaptive GMM. Dynamic PCA can also be achieved by lagging the data when performing PCA. For the GMM methods, the decision on the data type (whether scores, normalized or raw) is only available after selecting either approach.

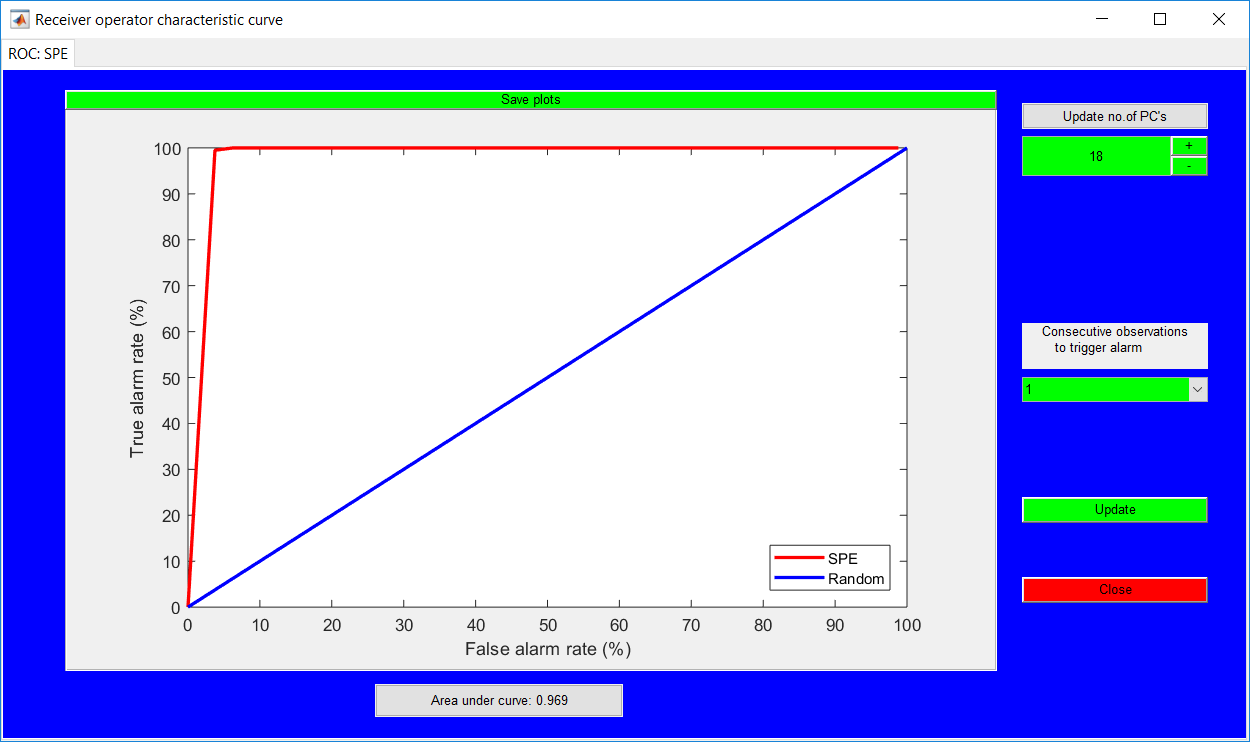
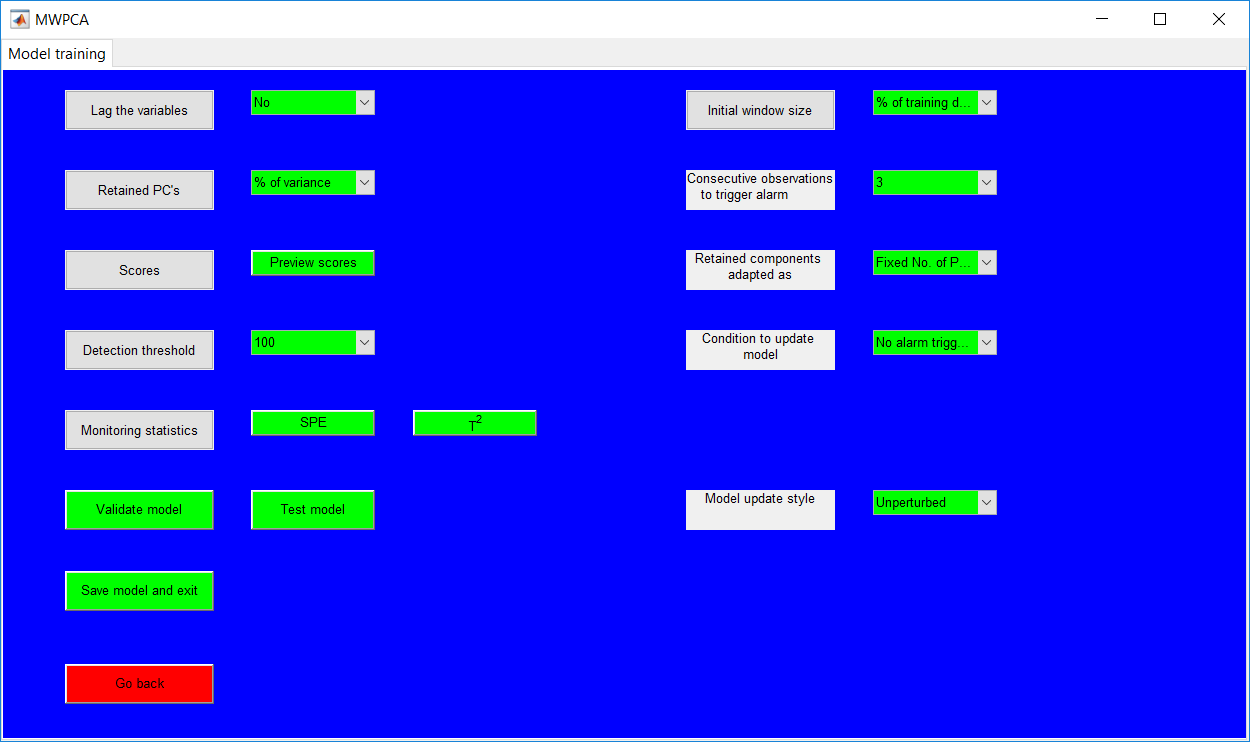
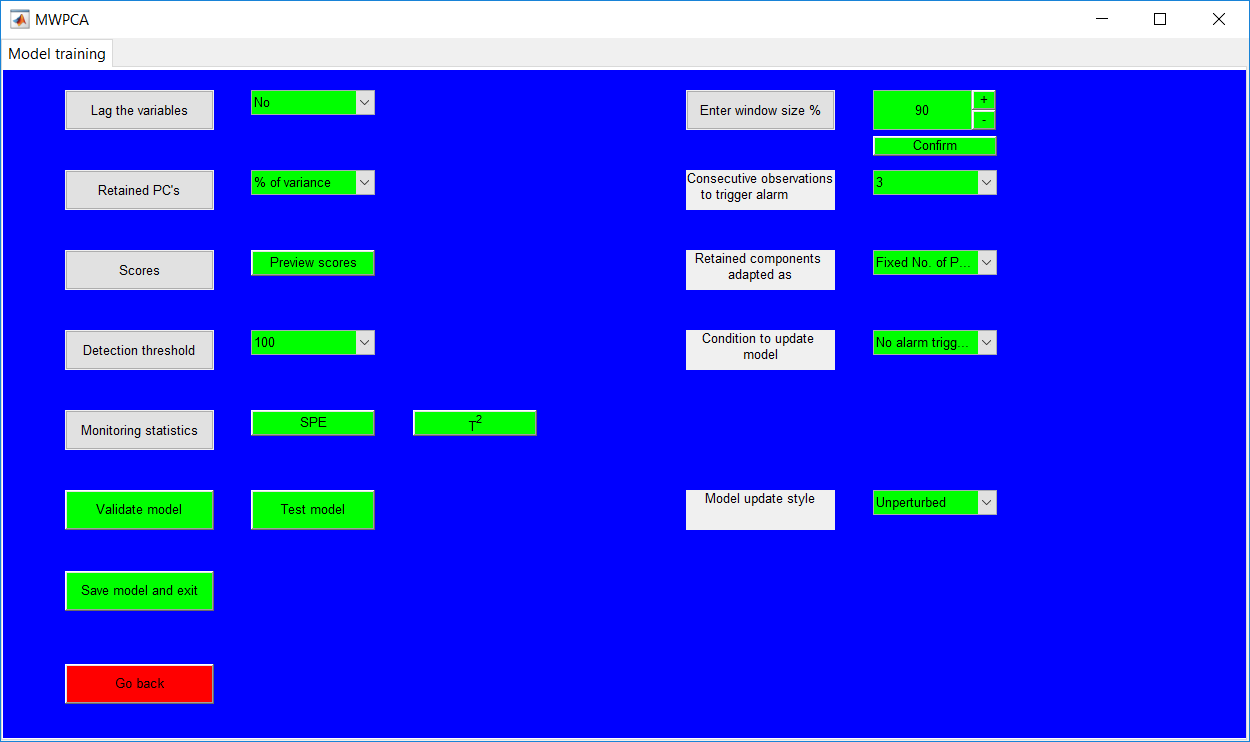
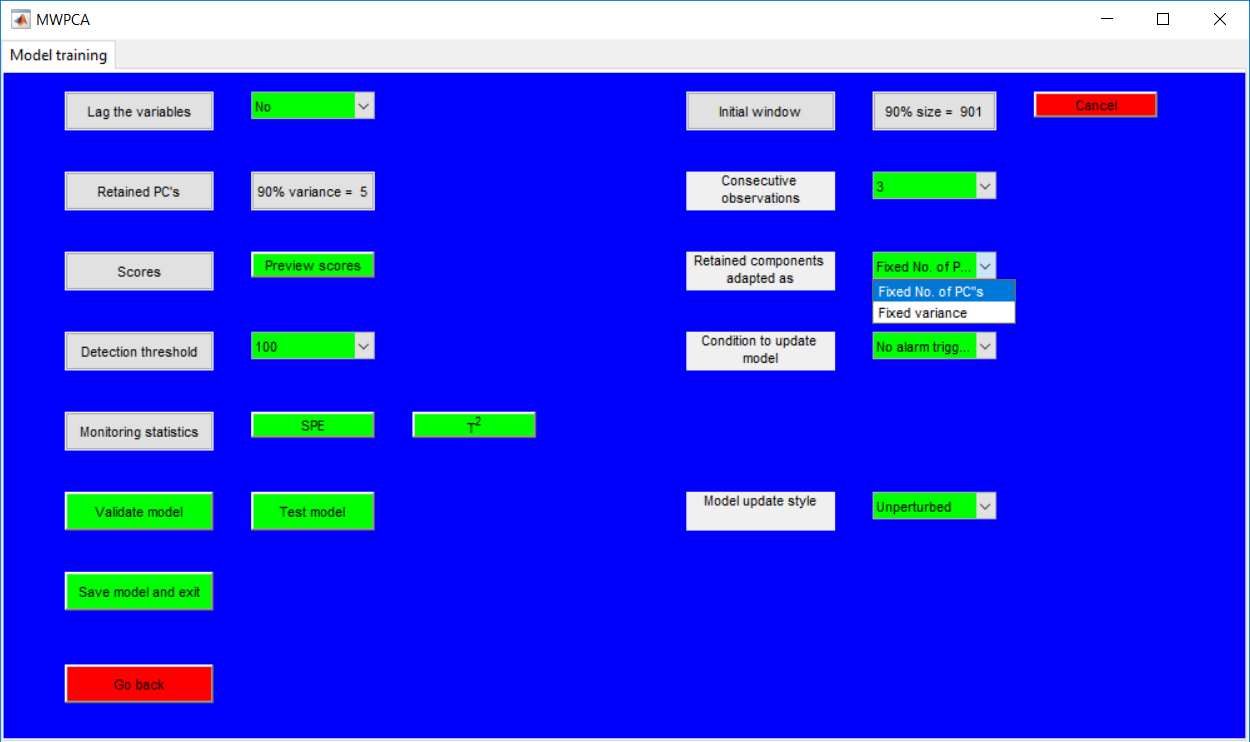




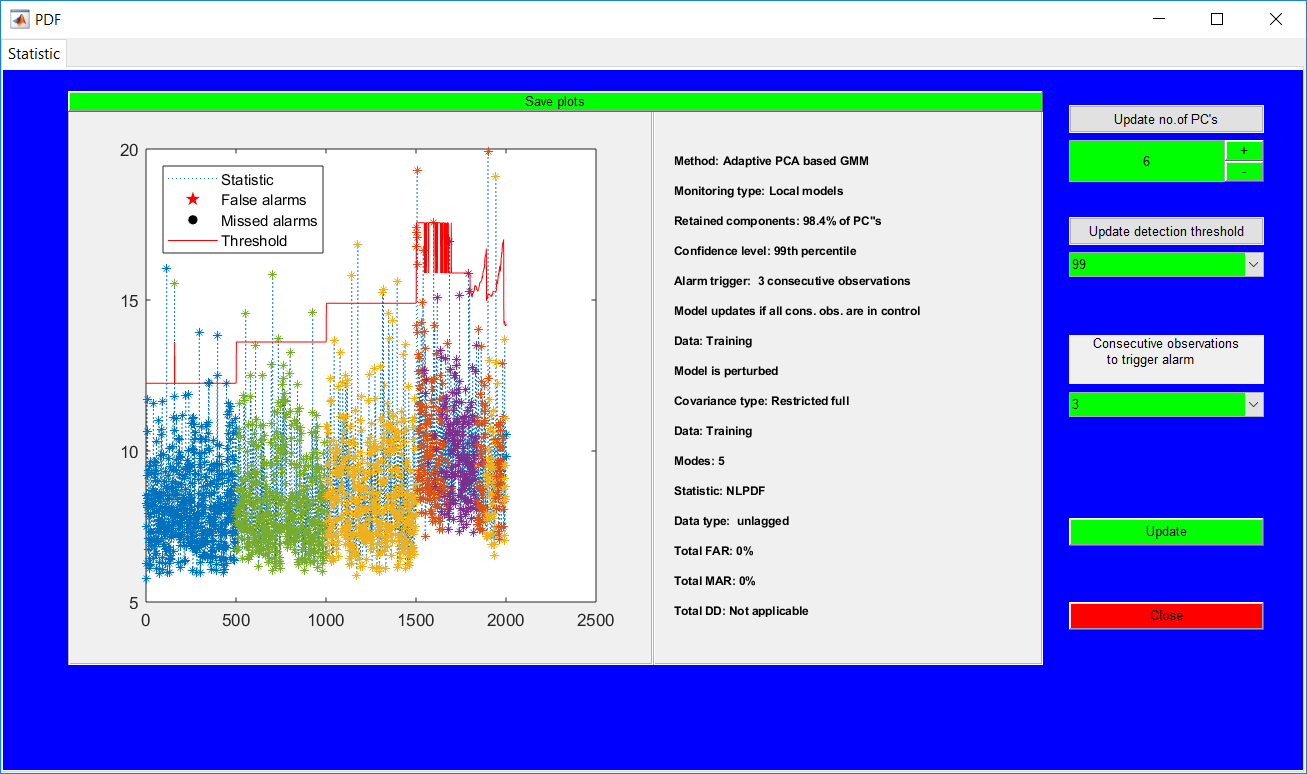
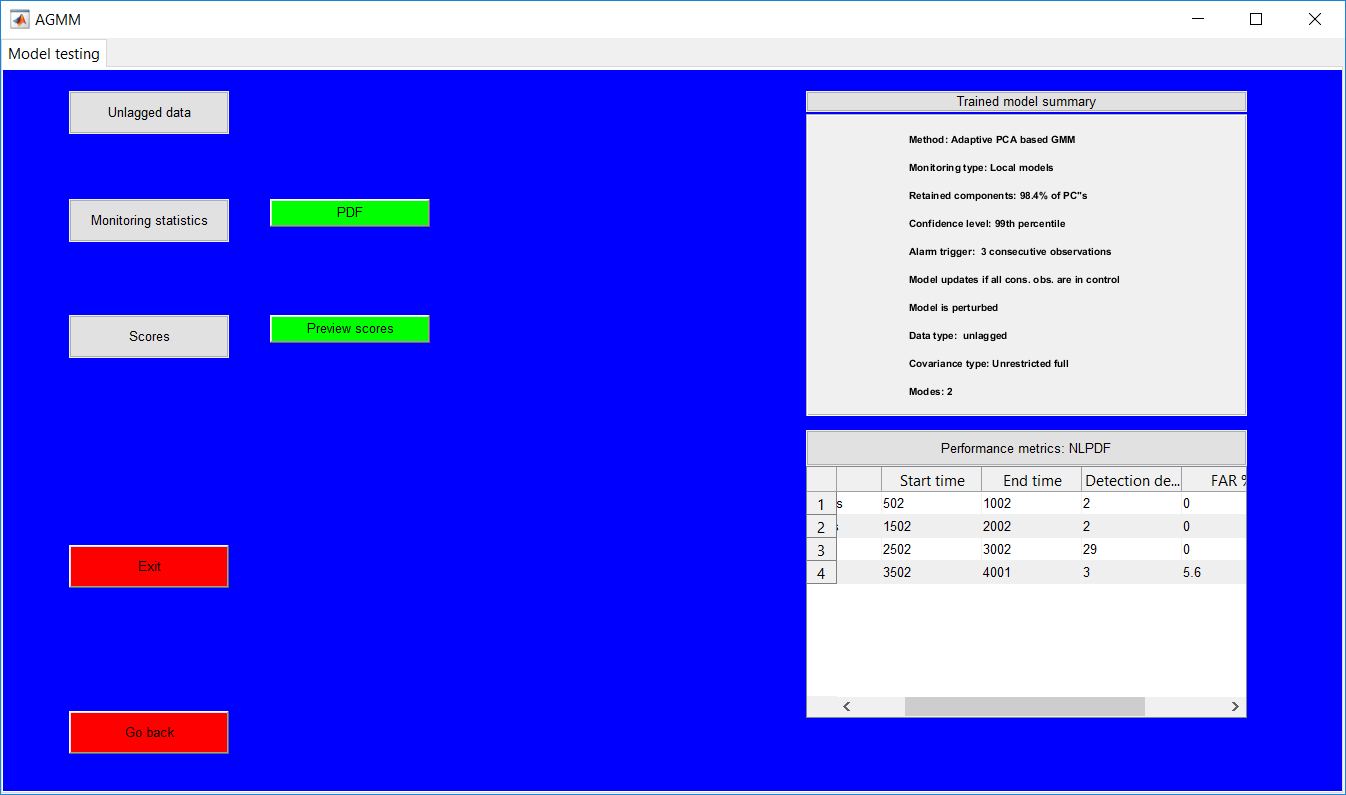

















.jpg)
.jpg)
.jpg)
.jpg)
.jpg)




PRINCE ADDO
10811 83 Ave NW, Edmonton, AB| +1-587-99172 | karimprinceaddo@yahoo.com|Personal webpage: princeaddo.cf
RESEARCH INTERESTS
Having a background in the following areas: modelling, machine learning, and graphical user interface with application to monitoring and control of chemical and mining processes; and website, software and application development, Prince seeks to develop further expertise through positions in website and application development, and process improvement and control. Special interests include fault detection and diagnostics, data analytics, graphical user interface development, and full-stack website development.
EDUCATION
PhD, Process Control 09/2020 – Present
Soft sensor development for Alberta oil sands.
University of Alberta, Canada
Master of Engineering, Extractive Metallurgy–Full Research 01/2017 – 03/2019
Thesis title: Adaptive process monitoring using principal component analysis and Gaussian mixture models.
Grade: Pass
Stellenbosch University, South Africa
Bachelor of Science, Petrochemical Engineering 09/2012 – 05/2016
Class: First Class Honours
Class Rank: 1 of 67
Kwame Nkrumah University of Science and Technology (KNUST), Ghana
CONFERENCE PUBLICATION
Addo P., Auret L., Kroon S., & McCoy J.T. (2018, October). Adaptive process monitoring using principal component analysis and Gaussian mixture models. Presentation at the Control Systems Day of the South African Council for Automation and Control, Stellenbosch, SA.
Addo P., Wakefield B., Auret L., Kroon S., & McCoy J.T. (2017, August). Adaptive process monitoring using principal component analysis, a milling circuit focus. Presentation and poster presented at the Minerals Research Showcase of the Southern African Institute of Mining and Metallurgy, Cape Town, SA.
AWARDS
- University of Alberta Doctoral Recruitment Scholarship, ($15,000 per annum) 2020 – Present
- The Centre for Artificial Intelligence Research (CAIR) bursary, CAIR-South Africa (R90,000 per annum) 2017 – 2018
- Best student award, College of Engineering, KNUST (College Awards) 2012 – 2016
- Ing. Dr Adu Amankwah award for the best graduating student, Dept. of Chemical Engineering, KNUST 2016
ACHIEVEMENTS
- Founder and lead developer for Ghanaian website and software development start-up company – Ultimate Developers (https://ultimatedevelopers.digital/).
- Developed a non-isothermal continuous stirred tank reactor simulator which is available for open access (see https://prince-addo.github.io/).
- Developed a process monitoring toolbox which is available for open access (see https://prince-addo.github.io/).
RESEARCH EXPERIENCE
Academic
Masters work 01/2017 – 03/2019
Adaptive process monitoring using principal component analysis and Gaussian mixture models.
Worked on improving process monitoring performance in process industries (mainly chemical and mining), by developing process monitoring models which incorporate process changes and update the model parameters in real time.
Undergraduate Honours Research Thesis 09/2015 – 05/2016
Plant design for styrene production
Served as a project leader in the design of a plant to produce styrene in Ghana, carrying out the required feasibility studies, economic and environmental impact assessments. The final thesis was assessed in through a thesis defence.
Engineering in Society Project 05/2013 – 09/2013
Pyrolysis of plastic waste into fuel oil
Investigated the feasibility of converting locally produced plastic waste (generated in communities) into a mixture of synthetic crude oil. The result of this study was used in the development of a pilot programme for a first-year project to help students identify the application of engineering to everyday challenges– and was presented to the College of Engineering, KNUST.
Industrial
Chemical Engineer Intern, Genser Energy, Ghana. 06/2014 – 08/2014
Projects undertaken:
Assessment of binders for coal briquettes
Investigated the performance of local binders for the production of coal briquettes in power production for GP Chirano Plant, a 30.0MW Steam Turbine Plant.
Assessment of biomass for coal co-firing
Investigated the performance of different biomasses to be combined with coal for power production.
WORK EXPERIENCE
Genser Energy, Accra, Ghana private power producer in Africa
Chemical engineer intern: 6/2014 – 8/2014
- Treated coal and installed new machinery at the storage facility.
- Researched on suitable binders for coal briquettes.
- Researched on suitable renewable resources for co-firing in a gasification plant to produce power.
PROGRAMMING SKILLS
MATLAB
PHP
Python
JavaScript